Đặt vấn đề
Trước đây người ta giải quyết bài toán tìm đường bằng cách sử dụng các thuật toán tìm đường cổ điển. Tuy nhiên các thuật toán tìm đường có rất nhiều hạn chế ví dụ như đòi hỏi môi trường phải xác định và cố định và không xử lý được nhiều tình huống thực tế. Với sự phát triển của trí tuệ nhân tạo, ngày nay các phương tiện với sự trợ giúp của máy tính có thể “học”, hay nói cách khác là tự tìm ra được quy luật hành động nói chung hay tìm đường nói riêng thông qua các kinh nghiệm thu được từ những hành động được thực hiện trước đó. Cách học từ những kinh nghiệm trong quá khứ này được gọi là học tăng cường. Có nhiều phương pháp học tăng cường khác nhau, trong đó phương pháp Q-learning là có hiệu quả nhất trong việc giải quyết bài toán tìm đường. Nội dung của bài toán mà nhóm chọn là để minh họa cho tính hiệu quả của phương pháp Q-learning và một số biến thể của phương pháp này để giải quyết bài toán tìm đường trong những môi trường đặc biệt như mạng máy tính hay multi-agent.
II. Phương Pháp Học Tăng Cường
Phương pháp học tăng cường là một phương pháp phổ biến để giải các bài toán quyết định Markov.
2.1 Bài toán quyết định markov
Bài toán quyết định Markov liên quan đến lớp bài toán trong đó một tác tử (người học hoặc máy học) rút ra kết luận trong khi phân tích một chuỗi các hành động của nó cùng với tín hiệu vô hướng từ môi trường (những gì bên ngoài tác tử)
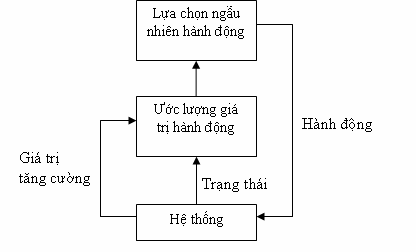
Lược đồ tương tác tác tử-môi trường như sau:

Hình 1: Mô hình tương tác giữa tác tử và môi trường
Trong lược đồ trên, tác tử và môi trường tác động lẫn nhau tại mỗi bước trong chuỗi các bước thời gian rời rạc, t = 0, 1, 2, 3, …Tại mỗi bước thời gian t, tác tử nhận một số biểu diễn về trạng thái của môi trường, st∈S, với S là tập các trạng thái có thể, và trên đó lựa chọn một hành động at∈A(st), với A(st) là tập các hành động có hiệu lực trong trạng thái st. Mỗi bước thời gian tiếp theo, tác tử nhận một giá trị tăng cường rt+1∈R (giá trị học được phản hồi về cho tác tử) và tự nó tìm ra một trạng thái mới st+1.
Tại mỗi bước tác tử thực hiện ánh xạ từ các trạng thái đến các hành động có thể lựa chọn. Phép ánh xạ này được gọi là chiến lược của tác tử, kí hiệu là πt với πt(s,a) là xác suất thực hiện hành động at=a khi st=s. Như vậy, bài toán quyết định Markov thực chất có thể được phát biểu như sau:
Biết - Tập các trạng thái: S
- Tập các hành động có thể: A
- Tập các tín hiệu tăng cường (mục tiêu).
Bài toán Tìm π: S→A sao cho R lớn nhất
1.2 PHƯƠNG PHÁP HỌC TĂNG CƯỜNG
1.2.1 Ý tưởng chung
Có hai phương pháp thường được sử dụng để giải các bài toán quyết định đó là tìm kiếm trong không gian chiến lược và tìm kiếm trong không gian hàm giá trị hay còn gọi là “phép lặp chiến lược” và “phép lặp giá trị”. Hai phương pháp này chính là các giải thuật học tăng cường đặc trưng. Ngoài ra còn xuất hiện một hương pháp lai giữa hai phương pháp trên: Actor-Critic learning.
Cơ chế chung của phép lặp chiến lược và phép lặp giá trị như sau:
Ý tưởng là ở chỗ, bắt đầu từ một chiến lược bất kỳ π và cải thiện nó sử dụng hàm giá trị trạng thái Vπ để có một chiến lược tốt hơn π’. Chúng ta sau đó có thể tính Vπ’ và cải thiện nó với một chiến lược tốt hơn nữa π’’,…Kết quả của tiến trình lặp này, chúng ta có thể đạt được một chuỗi các bước cải thiện chiến lược và các hàm giá trị.
Thuật toán lặp chiến lược:
(a) Bắt đầu với một chiến lược bất kỳ π.
(b) Lặp
Đánh giá chiến lược π.
Cải tiến chiến lược tại mỗi trạng thái.
Đến tận khi chiến lược không có khả năng thay đổi.
Trong thuật toán lặp chiến lược ở trên có đề cập đến một số khái niệm liên quan đó là đánh giá chiến lược và cải tiến chiến lược.
Đánh giá chiến lược
Chính là quá trình tính toán hàm giá trị trạng thái Vπ cho một chiến lược π bất kỳ. Nó được biết đến là phương trình Bellman:

Đây là một hệ thống các phương trình tuyến tính đồng thời. Lời giải của nó không quá phức tạp và có thể tìm được bằng cách sử dụng một trong các phương pháp giải hệ thống các phương trình tuyến tính. Lời giải có thể tìm được bằng việc tạo ra một chuỗi các hàm giá trị xấp xỉ V0,V1,V2,…
Xấp xỉ khởi tạo V0 được chọn ngẫu nhiên. Nếu có một trạng thái kết thúc nó sẽ nhận giá trị 0. Mỗi xấp xỉ thành công đạt được bằng cách sử dụng phương trình Bellman cho Vπ như là một luật cập nhật:

Bước lặp kết thúc khi độ lệch cực đại giữa hai hàm giá trị thành công nhỏ hơn một giá trị đủ nhỏ ε.
Cải tiến chiến lược
Chính là quá trình tạo một chiến lược mới cải tiến dựa trên chiến lược gốc bằng cách sử dụng thuật toán tham lam đối với hàm giá trị của chiến lược gốc. Với một chiến lược π cho trước, có thể tìm ra một chiến lược tốt hơn π’ sao cho Vπ’ > Vπ. Điều này đạt được bằng cách chọn theo tiên đoán một hành động tại một trạng thái riêng biệt hoặc bằng cách xem xét sự thay đổi tại tất cả các trạng thái và đối với tất cả các hành động có thể, lựa chọn tại mỗi trạng thái hành động xuất hiện tốt nhất dựa theo hàm giá trị hành động cho chiến lược π Qπ(s,a). Chiến lược π’ là tham lam nếu:

Trong phương trình trên, arg maxa chỉ ra giá trị của a tại đó biểu thức đạt cực đại. Chiến lược tham lam thực hiện hành động tốt nhất sau mỗi bước dựa theo Vπ.
Tóm lại, trong phép lặp chiến lược, giá trị của chiến lược chính là kết quả của hệ thống các phương trình tuyến tính. Sau đó, với mọi trạng thái, chúng ta sẽ quan sát liệu rằng có thể cải thiện chiến lược trong khi chỉ thay đổi hành động bắt đầu hay không. Phép lặp chiến lược là nhanh khi không gian hành động là nhỏ và đôi khi chỉ cần vài bước lặp là đủ, mặt khác phương pháp này là khá đắt thậm chí khó thực hiện trong trường hợp không gian hành động lớn.
Trong phương pháp này, chúng ta không cố gắng quyết định chiến lược một cách rõ ràng, mà sẽ quyết định hành động có giá trị tối ưu cho mọi trạng thái. Thuật toán lặp giá trị sinh ra từ dạng đệ qui của hàm giá trị trạng thái tối ưu Bellman. Phương trình chi phối thuật toán lặp giá trị như sau:

Người ta đã chứng minh được rằng giải thuật này hội tụ tại một số hữu hạn các bước lặp để đạt tới đích là chiến lược tối ưu, chuỗi {Vk} hội tụ đến giá trị trạng thái tối ưu V*. Phép lặp giá trị kết hợp một cách hiệu quả cả việc đánh giá chiến lược và cải thiện chiến lược.
Thuật toán lặp giá trị
(a) Khởi tạo V ngẫu nhiên cho mọi trạng thái
(b) Lặp
Với mỗi trạng thái s:

Đến tận khi độ lệch cực đại giữa hai hàm giá trị thành công nhỏ hơn một giá trị đủ nhỏ ε
(c) Đầu ra: Một chiến lược π sao cho

Lưu đồ hoạt động của các thuật toán dựa trên lặp giá trị được biểu diễn trong hình sau:

Hình 2: Lưu đồ hoạt động của thuật toán lặp giá trị
2.2.2 Phân loại thuật toán học tăng cường
Các thuật toán học tăng cường được chia thành hai loại chính đó là: học dựa trên mô hình (model based) và học không có mô hình (model free). Đại điện cho kiểu học dựa trên mô hình phải kể đến phương pháp quy hoạch động (Dynamic Programming-DP), đại diện cho kiểu học không có mô hình là phương pháp Monte Carlo và phương pháp TD (Temporal Difference).
Phương pháp này thực hiện học theo mô hình và sử dụng nó để quyết định chính sách tối ưu. Tác tử ước lượng mô hình từ các quan sát về cả khả năng chuyển đổi trạng thái và hàm tăng cường. Sau đó sẽ sử dụng mô hình ước lượng này như là mô hình thực tế để tìm ra chiến lược tối ưu .
Một cách cụ thể, tác tử tiến hành lập kế hoạch và biên dịch kết quả sang một tập các phản hồi nhanh hoặc các luật tình huống – phản hồi, sau đó sẽ được sử dụng trong quyết định thời gian thực. Cách tiếp cận này tuy nhiên bị giới hạn vào sự phục thuộc của nó vào một mô hình hoàn thiện về môi trường.
Phương pháp này tìm thấy chính sách tối ưu mà không phải học theo mô hình. Tác tử học các giá trị hành động mà không có mô hình về môi trường được mô tả bởi Pass’ và Rass’. Trong phương pháp này tác tử tương tác trực tiếp với môi trường và biên dịch thông tin nó thu thập được thành một cấu trúc phản hồi mà không có học từ mô hình. Trong phương pháp này, các bước chuyển đổi trạng thái và các giá trị phản hồi tác tử quan sát thay thế cho mô hình môi trường.
III. Phương pháp Q-Learning
Đây là phương pháp học theo kiểu off-policy. Quá trình học tăng cường có thể được thực hiện theo hai cách: off-policy và on-policy. On-policy sử dụng một luật chọn hành động để thực hiện các bước hành động để tối ưu hóa chính luật chọn hành động đó. Phương pháp off-policy sử dụng một luật chọn hành động để thực hiện các hành động nhưng với mục đích là để tối ưu hóa một luật chọn hành động khác.
Phương pháp này sử dụng hàm Q (action-state value function). Hàm Q được xác định bằng phương pháp Q-learning như sau:

Với γ là giá trị khấu hao cho giá trị Q của bước tiếp theo như đã được trình bày ở phần trước, và α là: “step size” - tham số đưa thêm vào để điều chỉnh mức độ tối ưu của quá trình học. Luật hành động học được chính là tập các hành động tại từng vị trí mà Q(s,a) tại vị trí đó lớn nhất .
Với cách điều chỉnh giá trị của hàm Q theo từng bước như vậy ta có thể mô tả thuật toán như sau: đầu tiên ta gán giá trị Q ban đầu cho các vị trí. Vị trí đích có giá trị phản hồi (reward) rất lớn. Vị trí “nguy hiểm” có giá trị âm rất lớn. Các vị trí khác có giá trị phản hồi là 1. Khi Tác tử nhảy vào vị trí nào thì nhận được giá trị phản hồi của vị trí đó. Sau đó ta thực hiện lặp đi lặp lại các quá trình thực hiện hành động và cứ sau mỗi bước thực hiện hành động thì lại điều chỉnh lại giá trị hàm Q cho các vị trí liên quan đến hành động vừa được thực hiện. Luật chọn hành động dùng để học thông thường là ε-greedy.
Toàn bộ quá trình thực hiện thuật toán cho một quá trình (episode) được trình bày như sau:
Gán giá trị khởi đầu cho Q(s, a)
- Repeat (cho từng episode)
Đặt s vào vị trí bắt đầu
- Repeat (cho từng bước của episode)
Chọn hành động a (chẳng hạn bằng phương pháp ε-greedy)
Thực hiện bước a, nhận được giá trị phản hồi r và vị trí tiếp theo s’
Điều chỉnh giá trị hàm Q:

Until s là vị trí đích hoặc đã thực hiện hết số lượng bước giới hạn của episode.
Với phương pháp này thì luật chọn hành động để học thông thường được thực hiện theo phương pháp ε-greedy trong khi việc điều chỉnh giá trị hàm Q ứng với mỗi cặp vị trí – hành động (s,a) được thay đổi dựa trên giá trị Q tối ưu của cặp (s’,a’) kế tiếp mà hành động a’ không nhất thiết là hành động được chọn theo “policy” đang được áp dụng. Do đó phương pháp này thuộc loại off-policy.
Xét về lý thuyết ta có thể nhận thấy phương pháp kiểu off-policy cho phép khám phá được nhiều hơn so với on-policy nên khả năng tìm ra được những lối đi mới có quãng đường ngắn hơn là cao hơn so với phương pháp on-policy. Thực nghiệm cũng xác nhận quan điểm này.
Để minh họa cho lập luận trên và đồng thời để mô tả cách áp dụng thuật toán Q-learning vào bài toán tìm đường thông thường ta có thể nghiên cứu kết quả từ thực tế từ bài toán kinh điển gridworld bằng phương pháp Q-learning và bằng một phương pháp khác theo kiểu on-policy và so sánh kết quả. Phương pháp on-policy được chọn là SARSA – là phương pháp học rất hiệu quả theo kiểu on-policy. Với phương pháp SARSA thì hàm Q được điều chỉnh sau mỗi bước thực hiện hành động theo công thức sau:

Bài toán được thực hiện bằng việc cho tác tử tìm đường di chuyển từ điểm khởi đầu đến điểm đích với các chướng ngại vật. Tác tử sẽ khởi động từ vị trí ô xanh và đích là ô đỏ. Các ô màu xám biểu thị cho vật cản. Các bước đi gồm có sang trái, sang phải, đi lên, đi xuống. Luật hành động chính là hướng đi tối ưu cho từng vị trí để đến được đích với số bước đi ngắn nhất (hình vẽ 2). Quá trình thực hiện được chia thành nhiều giai đoạn (episode), mỗi giai đoạn được kết thúc sau khi tác tử đến được đích hoặc tác tử thực hiện hết một số lượng bước được quy định. Trong quá trình thực hiện các bước đều có điều chỉnh lại giá trị hàm Q cho các vị trí liên quan. Thực nghiệm được tiến hành với các tham số thay đổi nhằm kiểm tra hiệu quả của từng thuật toán với từng điều kiện nhất định. Trong quá trình thực nghiệm thì số lượng giai đoạn cũng như bước nhảy cho mỗi giai đoạn được chọn thích hợp để thể hiện rõ sự khác biệt về kết quả các phương pháp học. Mỗi lần học thì kết quả được đo 3 lần và chọn ra kết quả tốt nhất. Bài toán được thực hiện cho cả 2 phương pháp SARSA và Q-learning, áp dụng phương pháp ε-greedy để chọn hành động và thay đổi giá trị các tham số α, γ, ε trong khoảng từ 0 - 1.
IV. Ứng Dụng Phương Pháp Q-Learning Vào Bài Toán Tìm Đường Đi Ngắn Nhất
Trong phần này chúng ta sẽ mô phỏng phương pháp học tăng cường cho bài toán tìm đường đi ngắn nhất. Với bài toán này, chúng ta có tập trạng thái S, tập các hành động A{trên, dưới, trái, phải},rmìn=-100,rđích=100, các giá trị phản hồi còn lại có giá trị là 0.
Thuật toán off-policy dùng cho TD Learning được dùng bài toán này có mã giã như sau:

Các tham số được sử dụng trong quá trình cập nhật giá trị Q là:
- α: hệ số học, nằm trong khoảng 0,1. Bằng 0 có nghĩa là giá trị Q không bao giờ được cập nhật, nghĩa là không có gì được học. Giá trị lớn, ví dụ
- 0.9 nghĩa là việc học xảy ra nhanh.
- γ: hệ số suy giảm, cũng nằm trong khoảng 0,1.
- maxα : giá trị tăng cường lớn nhất có thể đạt được trong trạng thái theo sau trạng thái hiện tại.
Các bước của thuật toán:
1. Khởi tạo bảng giá trị Q, Q(s,a).
2. Quan sát trạng thái hiện tại s.
3. Lựa chọn hành động a cho trạng thái dựa vào một trong các chiến lược lựa chọn hành động (ε-soft, ε-greedy hoặc softmax).
4. Thực hiện hành động và quan sát giá trị r cũng như trạng thái mới s’.
5. Cập nhật giá trị Q cho trạng thái sử dụng giá trị tăng cường được quan sát và giá trị tăng cường lớn nhất có thể cho trạng thái tiếp theo. Việc thực hiện được cập nhật dựa theo công thức mô tả ở trên.
6. Thiết lập trạng thái đến trạng thái mới và lặp lại quá trình này đến tận khi gặp được trạng thái kết thúc.

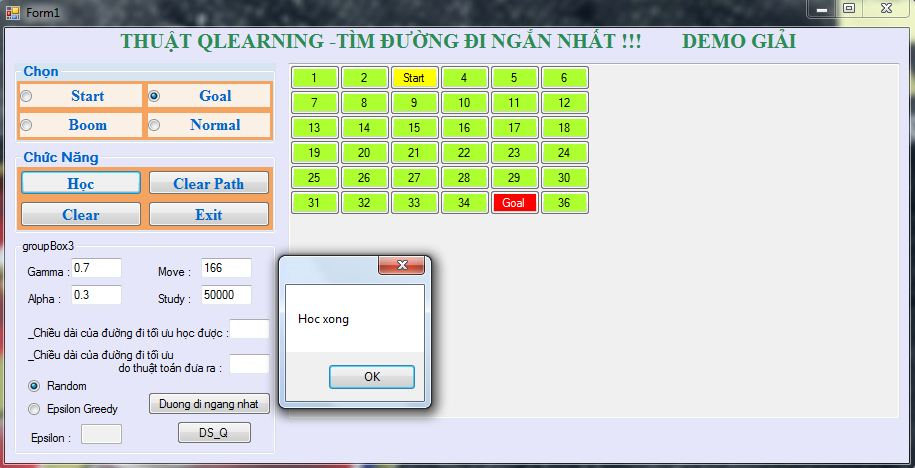
Giao diện chính chương trình
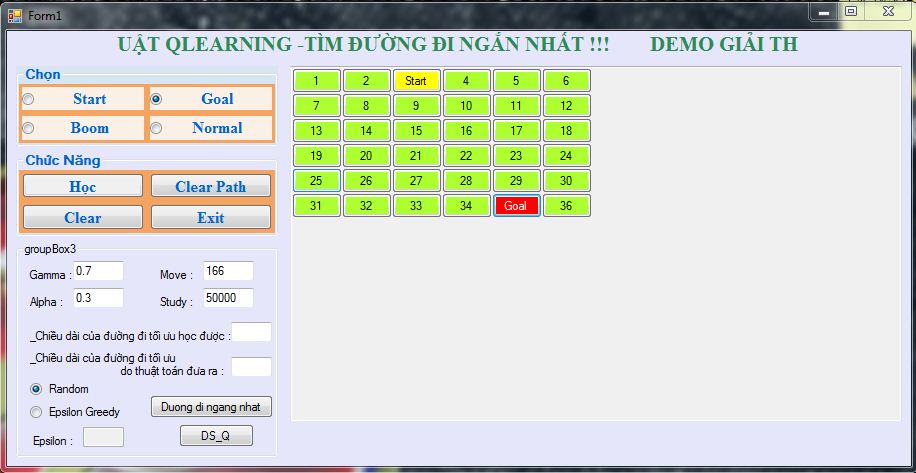
Sẽ có điểm bắt đầu và kết thúc, trạng thái của 1 ô có thể là normal hoặc goal. Ban đầu, chưa học nên sẽ không tìm thấy đường đi.

Không tìm thấy đường đi
Ta sẽ bắt đầu chọn các thông số để cho chương trình học.

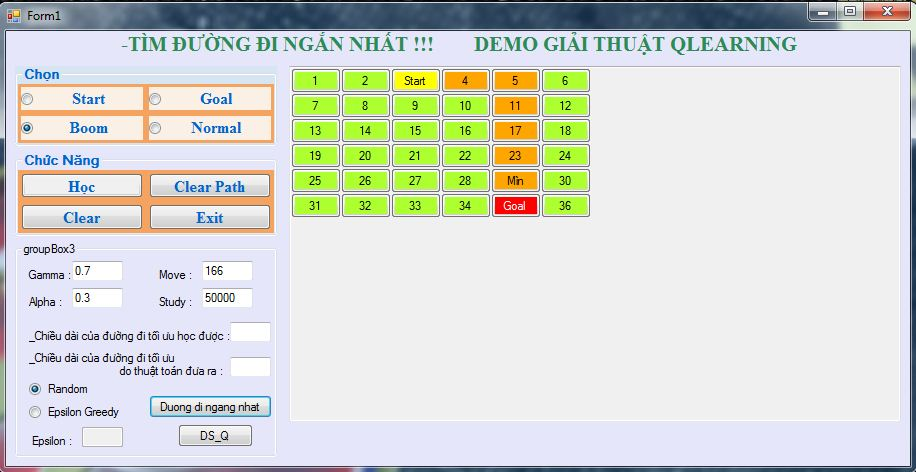
Sau khi đã được học thì sẽ tìm được đường đi ngắn nhất.

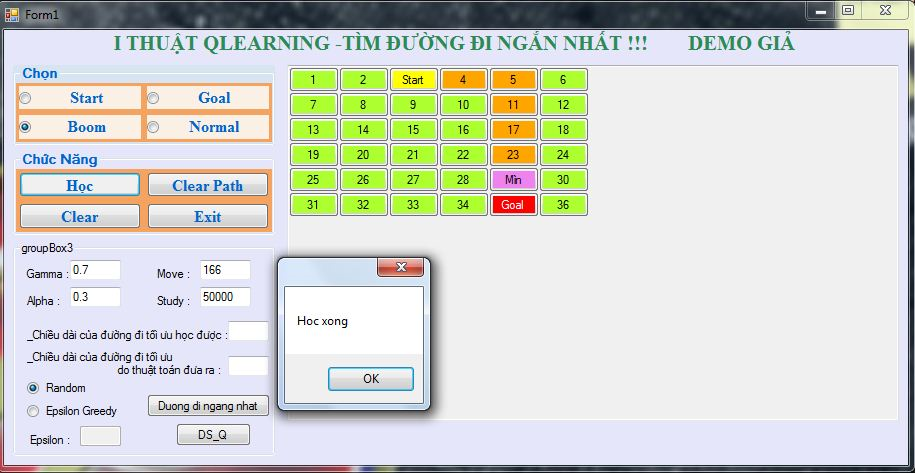
Giả sử ta đặt mìn vào một vị trí trên đường đi, thì chương trình sẽ cho kết quả như thế nào.

Lúc này, do chưa được học nên đường đi ngắn nhất vẫn sẽ qua vị trí mới đặt mìn và như vậy là sai.

Ta sẽ tiến hành cho chương trình học

Sau khi học xong và thực hiện tìm đường đi ngắn nhất thì nó sẽ tìm được đường đi chính xác.








")


/4.png "machinelearning-clustering-(gmm)")



")
.jpg "SVM (SUPPORT VECTORMACHINE)")

.jpg "PHƯƠNG PHÁP TẠO CÂY ĐỊNH DANH ID3")


























")




 trong deep learning")
 TRONG BÀI TOÁN KHAI THÁC TẬP LỢI ÍCH CAO")







