Lucene là một thư viện mã nguồn mở hỗ trợ việc tìm kiếm thông tin. Lucene cho phép chúng ta có thể tích hợp vào các ứng dụng. Lucene nguyên thuỷ được phát triển bằng ngôn ngữ Java, ngày nay Lucene được phát triển bằng nhiều ngôn ngữ khác nhau như Delphi, Perl, C#, C++, Python, Ruby và PHP…
Thành phần chức năng chính của Lucene bao gồm hai phần: thành phần tạo chỉ mục và thành phần tìm kiếm. Đây chính là hai thành phần quan trọng cho một hệ thống tìm kiếm.
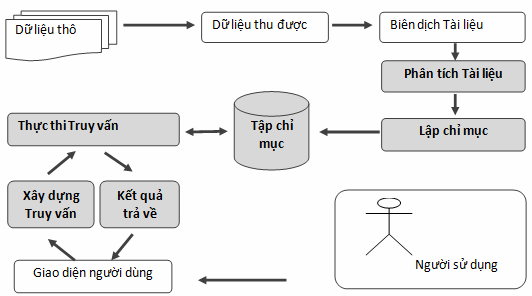
Hình 2.1. Các thành phần Lucene hỗ trợ cho hệ thống tìm kiếm
- Thành phần tạo chỉ mục:
- Directory: cho phép định nghĩa vùng nhớ, xác định nơi lưu trữ trên bộ nhớ ngoài và bộ nhớ trên RAM trong quá trình tạo chỉ mục.
- Document và Field: định nghĩa tài liệu và các trường thông tin của tài liệu sử dụng cho lập chỉ mục, sử dụng cho việc lấy kết quả trả về cho thành phần tìm kiếm.
- Analyzer: thực hiện chức năng xử lý và tách văn bản để lấy nội dung, chuẩn hóa, loại bỏ mục từ không cần thiết,… để chuẩn bị cho việc lập chỉ mục.
- IndexWriter: là phần chính trong thành phần tạo chỉ mục, nó thực hiện việc tạo mới hoặc mở chỉ mục, sau đó thực hiện thêm mới hoặc cập nhật nội dung của chỉ mục.
- Thành phần tìm kiếm:
- Term: Term là một đơn vị cơ bản của tìm kiếm, Term bao gồm tên và giá trị tương ứng.
- Query: bao gồm nhiều loại truy vấn khác nhau, nó chứa nhiều phương thức, nhưng hầu hết đều quan tâm đến việc thiết lập chỉ số Boost
- IndexSearcher: cho phép tìm kiếm trên tập chỉ mục do IndexWriter tạo ra, đây là thành phần chỉ thực hiện nhiệm vụ mở tập chỉ mục, không cho phép chỉnh sửa hay thay đổi.
- TopDoc: là một lớp đơn giản, dùng cho việc chứa các thứ hạng cao nhất của N tài liệu có liên quan đến truy vấn. Với mỗi đối tượng trong danh sách này sẽ cho một docID dùng để liên kết đến tài liệu.
- Lucene không phải là một ứng dụng hay một máy tìm kiếm hoàn chỉnh để người dùng có thể sử dụng ngay lập tức, Lucene chỉ là một thư viện cung cấp các thành phần quan trọng nhất của một máy tìm kiếm đó là tạo chỉ mục và thực hiện truy vấn.
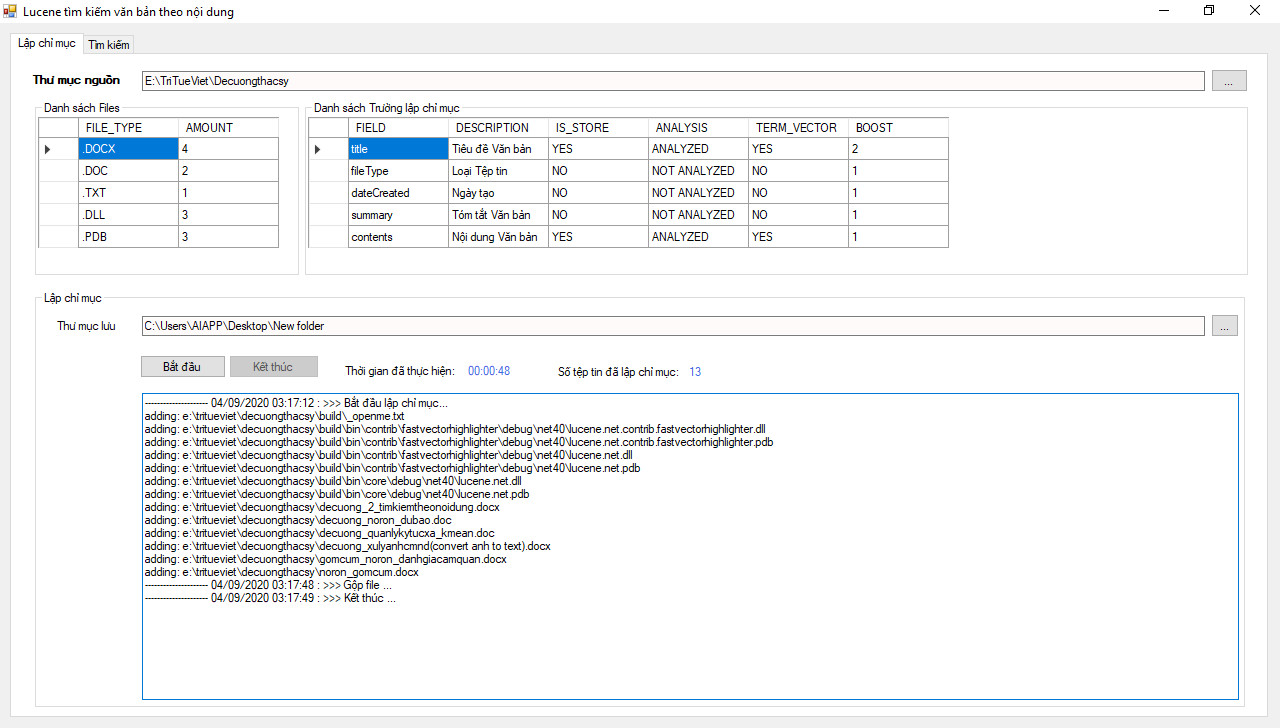
Lucene hỗ trợ hai cấu trúc chỉ mục: các chỉ mục đa tệp (multifile indexes) và các chỉ mục ghép (compound indexes). Chỉ mục đa tệp là cấu trúc chỉ mục đưa ra từ những phiên bản đầu tiên của Lucene ; cấu trúc chỉ mục ghép được đưa ra trong Lucene 1.3 và từ phiên bản 1.4 thì trở thành cấu trúc mặc định.
- Chỉ mục đa tệp: một chỉ mục đa tệp là một thư mục bao gồm các tệp chỉ mục
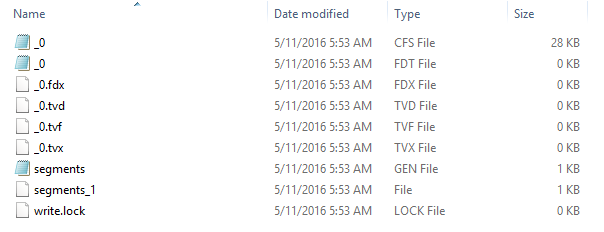
Hình 2.2: Ví dụ các tệp chỉ mục đa tệp
- Chỉ mục ghép: một chỉ mục ghép là một thư mục chứa một tệp .cfs duy nhất, cấu trúc chỉ mục ghép đóng gói các tệp chỉ mục riêng lẻ trong một tệp .cfs duy nhất.
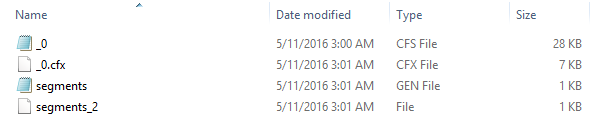
Hình 2.3: Ví dục các tệp chỉ mục ghép
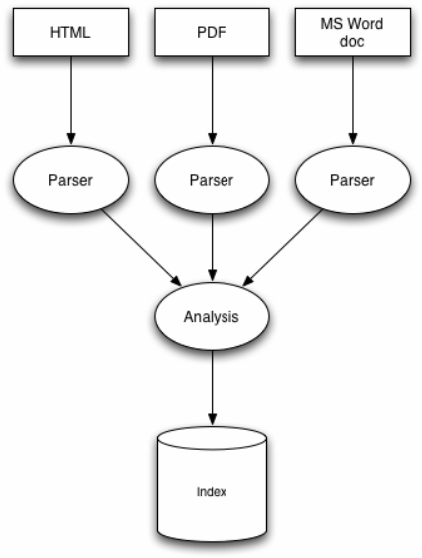
Hình 2.4: Quy trình đánh chỉ mục của Lucene
Quy trình đánh chỉ mục của Lucene gồm có 3 bước: Convert to text, Analysis và Writing index.
2.2.2.1 Convert to text:
Để Lucene có thể phân tích và đánh index, trước hết ta phải chuyển tài liệu về dạng văn bản thuần túy (.txt), vì tài liệu đầu vào có thể có rất nhiều định dạng khác nhau (PDF, word, excel,…..) nên bước này rất quan trọng.
2.2.2.2 Analysis:
Mỗi khi ta chuẩn bị cho việc index và tạo ra đối tượng Document với các Field, thì Lucene sẽ phân tích dữ liệu này sao cho phù hợp nhất với việc index. Để làm điều này, Lucene sẽ phân chia dữ liệu thành các chuỗi hoặc là các kí tự (tokenize) thông qua việc lựa chọn các toán tử thực thi trên chúng. Chẳng hạn như việc bạn phân tích thành các kí tự thường, hoặc bỏ đi các từ ngữ không có nghĩa… Lucene hỗ trợ ta 4 bộ phân tích dữ liệu: WhitespaceAnalyzer, SimpleAnalyzer, StopAnalyzer, StandardAnalyzer
-
- WhitespaceAnalyzer không thực hiện lowercase(chuyển tất cả sang ký tự thường ) , vẫn giữ dấu “-” , loại bỏ tất cả các khoảng trắng, và dựa vào các khoảng trắng để làm đường biên phân chia tokenize.
- SimpleAnalyzer thực hiện lowercase, vẫn giữ các từ nằm trong danh sách stop-word, dùng các ký tự không phải là các chữ cái alphabetic để làm đường biên phân chia tokenize.
- Cả SimpleAnalyzer và WhitespaceAnalyzer đều làm sai lệch tên của tên các công ty như ví dụ xy&z bị rã ra thành [xy] [z] , loại bỏ ký hiệu &.
- StopAnalyzer và StandardAnalyzer loại bỏ các từ nằm trong Stop-Word ví dụ như “the” ở ví dụ trên.
- StopAnalyzer chia các từ cơ bản trong dữ liệu đưa vào và lowercasing , còn loại bỏ những stop words. Đưa vào các từ English thuộc stopword vào trong StopAnalyzer
- StandardAnalyzer là bộ phân tích chung nhất , nền tảng gắn liền với analyzer trong Lucene. Tokenizing thông minh với các loại từ vựng, chữ cái, viết tắt của các chữ đầu dòng, tên công ty, địa chỉ email, tên miền , số, serial number, IP address, CJK (Chinese, Japanese, Korean) character. Loại bỏ các từ nằm trong stopword , vì vậy StandardAnalyzer thường là lựa chọn đầu tiên.
2.2.2.3 Writing index
Sau khi phân tích dữ liệu, Lucene sẽ lưu dữ liệu này theo cấu trúc inverted index(chỉ mục có thể nghịch đảo ). Cấu trúc này sẽ có hiệu quả để tiết kiệm dung lượng ổ đĩa và cho phép tìm kiếm nhanh hơn các từ khóa trong quá trình search.
Xây dựng và duy trì một inverted index là vấn đề trung tâm khi xây dựng một hệ thống tìm kiếm hiệu quả. Để lập chỉ mục một tài liệu, trước hết phải duyệt qua nó để tạo một danh sách các posting. Các posting mô tả các thể hiện của một từ trong một tài liệu; chúng thường gồm một từ, một mã tài liệu và có thể cả các vị trí hoặc tần số của từ đó trong tài liệu.
Lucene xây dựng nhiều phân đoạn chỉ mục và kết hợp chúng lại với nhau một cách định kỳ. Với mỗi tài liệu mới được lập chỉ mục, Lucene tạo một phân đoạn chỉ mục, nhưng nó sẽ nhanh chóng kết hợp các phân đoạn nhỏ với những phân đoạn lớn hơn - việc này giữ cho tổng số các phân đoạn luôn nhỏ nhằm đảm bảo tốc độ tìm kiếm vẫn nhanh. Để tối ưu chỉ mục cho tìm kiếm được nhanh, Lucene kết hợp tất cả các phân đoạn thành một, Lucene không bao giờ thay đổi ngay các phân đoạn mà nó chỉ tạo ra phân đoạn mới. Khi kết hợp các phân đoạn, Lucene ghi một phân đoạn mới và xoá những phân đoạn cũ
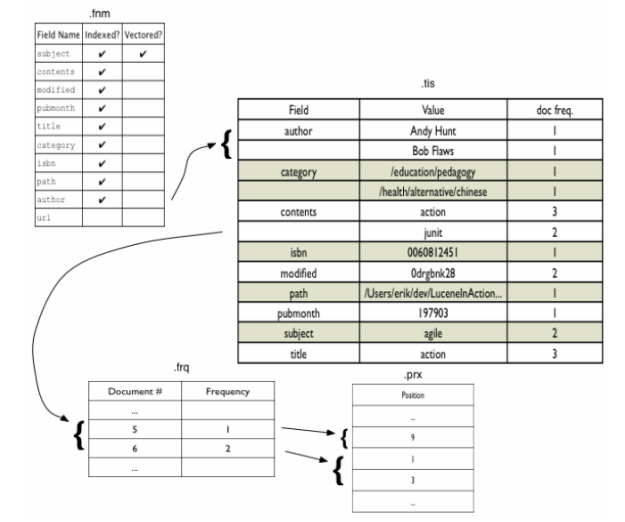
Hình 2.5: Ví dụ minh họa định dạng chỉ mục Lucene
- Tệp .fnm: Tệp .fnm bao gồm tất cả các tên trường được sử dụng. Mỗi trường được đánh dấu để thể hiện các thuộc tính của nó. Thứ tự các tên trường trong tệp .fnm được xác định trong quá trình lập chỉ mục và không cần thiết phải theo thứ tự abc.
- Tệp .tis: Tệp .tis chứa các term (tên trường và các giá trị) cùng tần số tài liệu (document frequency: số tài liệu chứa term này) của nó. Các term được sắp xếp theo theo thứ tự ABC của tên trường và giá trị trong một trường.
- Tệp .frq: Tệp frq chứa tần số term trong mỗi tài liệu. Tần số của một term trong một tài liệu được dùng làm thừa số để tính xếp hạng và thường tăng độ liên quan của một tài liệu khi nó có tần số cao
- Tệp .prx: Tệp .prx liệt kê vị trí của từng term trong một tài liệu.
Mô hình không gian véctơ đã được sử dụng rộng rãi trong lĩnh vực tìm kiếm thông tin và hầu hết các máy tìm kiếm đều sử dụng độ đo dựa trên mô hình này để xếp hạng các tài liệu. Mô hình này tạo ra một không gian trong đó cả các tài liệu và các truy vấn được biểu diễn bởi các véctơ term, trong đó các term được đánh trọng số. Ví dụ, một tài liệu D được biểu diễn bởi một véctơ có n trọng số D = (d1, d2, d3 , …, dn ), với n là số các term không trùng lặp trong tập tài liệu.
Mô hình không gian véctơ mang lại lược đồ đánh trọng số nhằm phân biệt tài liệu này với tài liệu khác, hầu hết là trọng số idf, với giả thiết rằng độ quan trọng của một term tỷ lệ thuận với số các thể hiện của term đó trong một tài liệu và tỷ lệ nghịch với số các tài liệu có chứa term đó.
Hai véctơ trong không gian véctơ càng gần nhau thì khả năng liên quan của tài liệu tương ứng càng cao. Trong mô hình không gian véctơ, có nhiều độ đo để tính độ đồng dạng này. Độ đo sự đồng dạng phổ biến nhất là hệ số côsin, hệ số này đo góc côsin giữa một véctơ tài liệu và véctơ truy vấn. Sau đó, các tài liệu được xếp hạng theo thứ tự các giá trị côsin giảm dần.
Giả sử cho câu truy vấn “gold silver truck” và 3 tài liệu:
D1: "Shipment of gold damaged in a fire"
D2: "Delivery of silver arrived in a silver truck"
D3: "Shipment of gold arrived in a truck
Các kết quả tính trọng số được tổng kết trong bảng
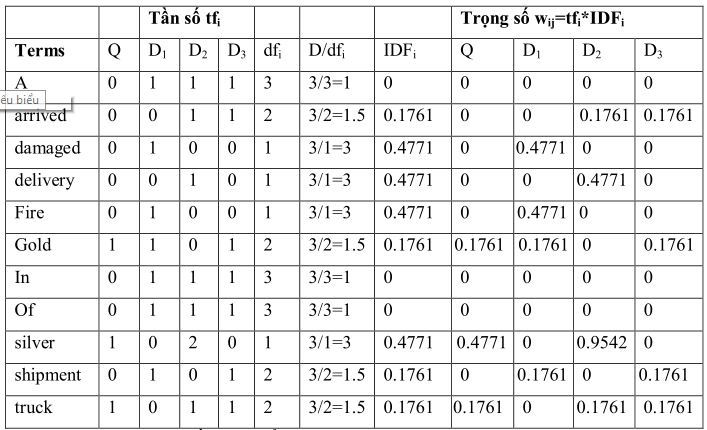
Hình 2.6: Kết quả tính trọng số
Cột 1 đến cột 5: Danh mục các thuật ngữ được xây dựng từ các tài liệu và tính tần số tfi cho câu truy vấn trong mỗi tài liệu Dj
Cột 6 đến cột 8: Là tần số tài liệu di của từng tài liệu. Từ đó tính IDFi = log(D/dfi) và D = 3.
Cột 9 đế cột 12: Là trọng số thuật ngữ được xác định bằng cách lấy tích tfi * IDFi . Các cột này có thể được xem như là một ma trận thưa, trong đó hầu hết các mục bằng 0.
Tính độ tương đồng
Để tính độ tương đồng, trước tiên tính tất cả các chiều dài vector cho mỗi tài liệu và câu truy vấn:

Tiếp theo tính tất cả các tích điểm (bỏ qua các tích 0)
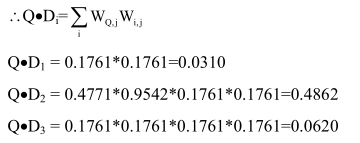
=> Các giá trị tương đồng
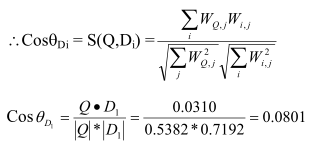
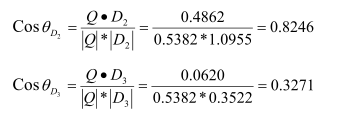
Cuối cùng sắp xếp thứ tự cho các tài liệu theo thứ tự giảm dần theo giá trị tương đồng:
Rank 1: Doc2 = 0.8246
Rank 2: Doc 3= 0.3271
Rank 3: Doc 1= 0.0801
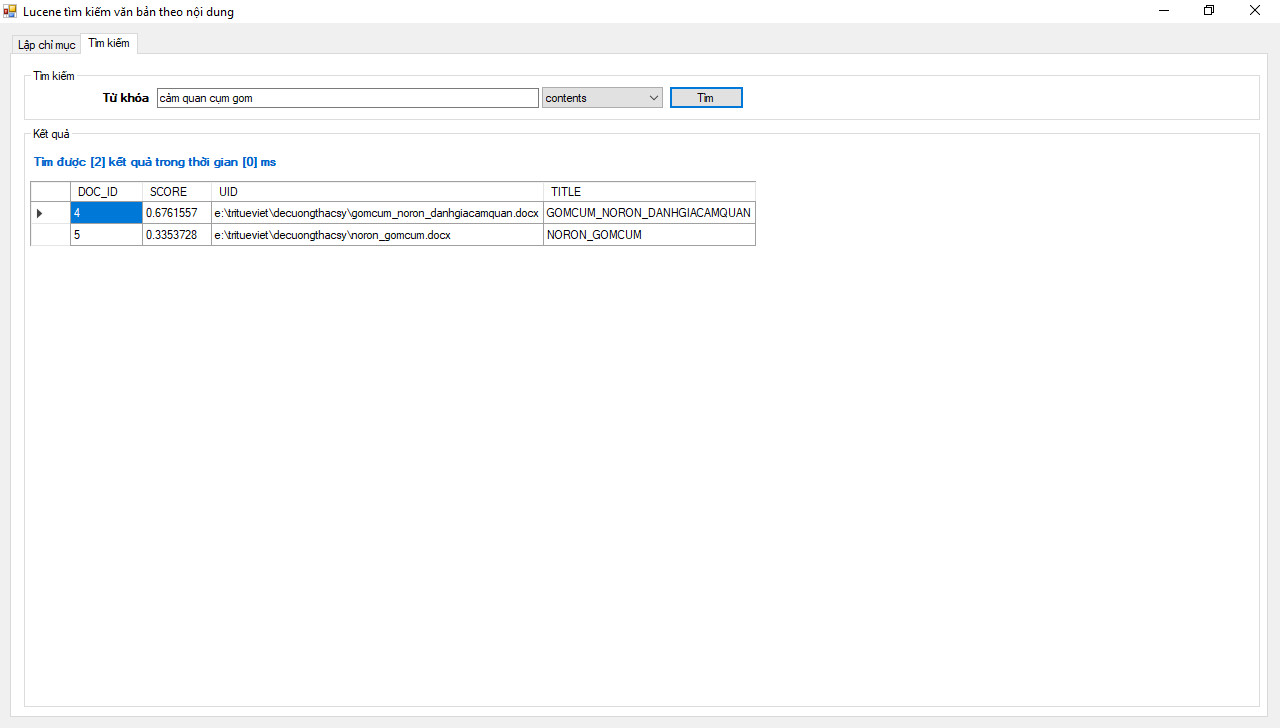
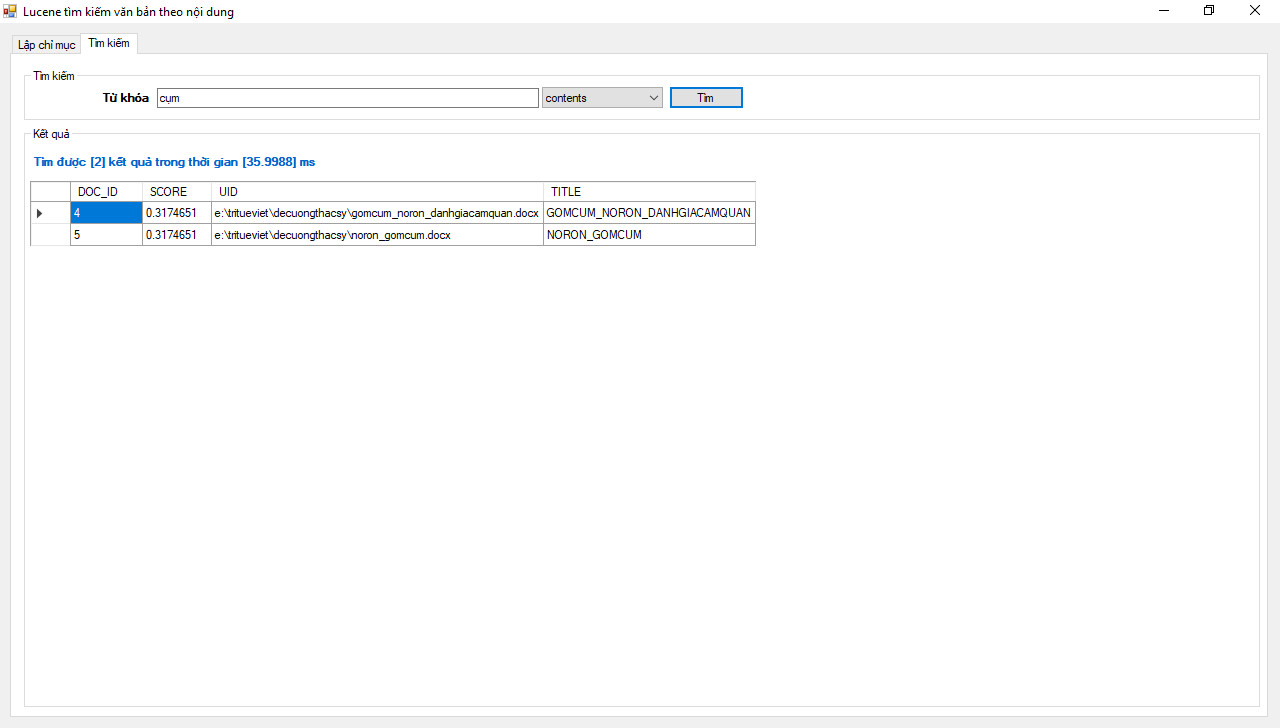
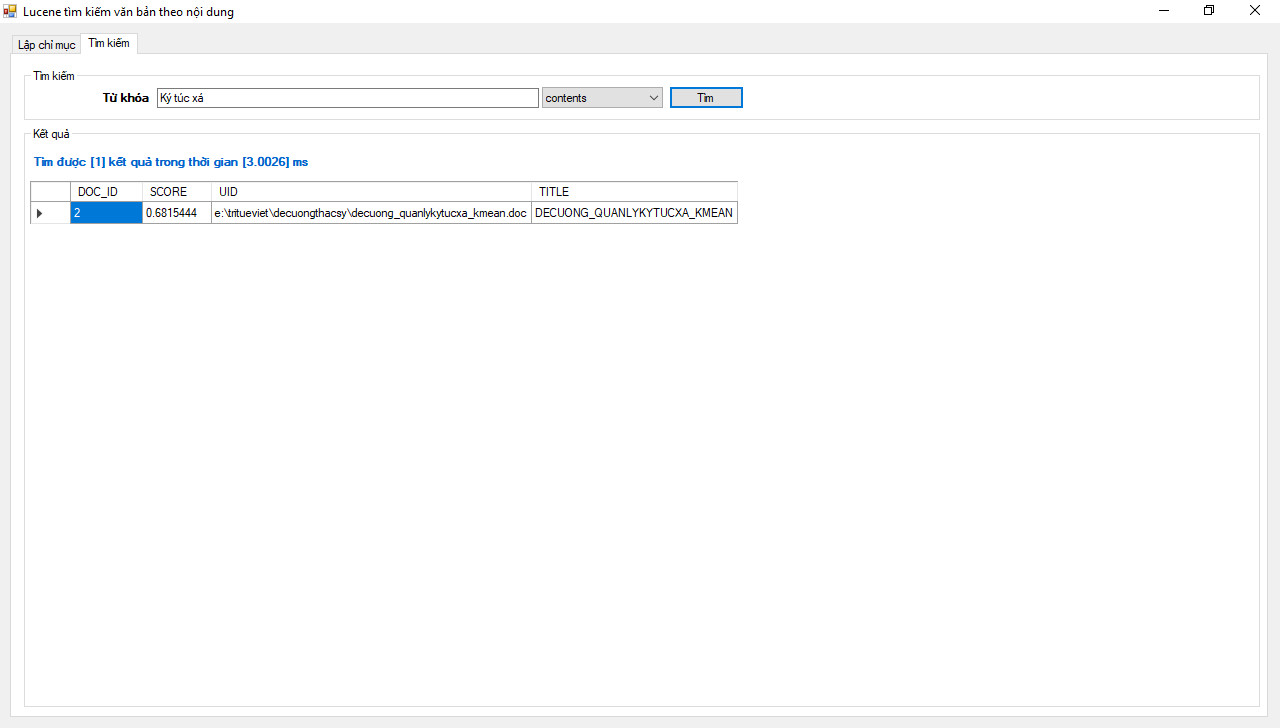
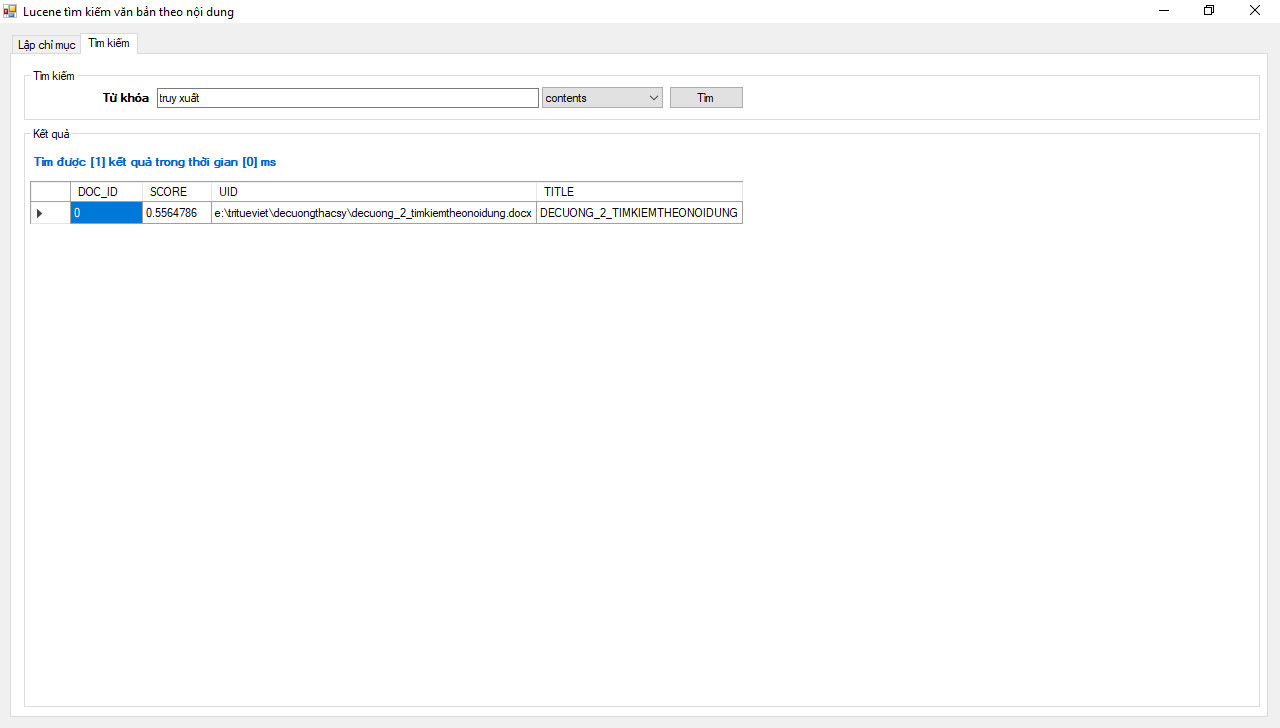






")


/4.png "machinelearning-clustering-(gmm)")



")
.jpg "SVM (SUPPORT VECTORMACHINE)")

.jpg "PHƯƠNG PHÁP TẠO CÂY ĐỊNH DANH ID3")


























")




 trong deep learning")
 TRONG BÀI TOÁN KHAI THÁC TẬP LỢI ÍCH CAO")







