PHẦN I. GIỚI THIỆU DATA.
- Giới thiệu về data
- Phân biệt nấm có thể được với nấm độc
- Bộ dữ liệu này bao gồm các mô tả về các mẫu giả định tương ứng với 23 loài nấm mang trong họ Nấm Agaricus và Lepiota được rút ra từ Hướng dẫn thực địa của Hiệp hội Audubon về Nấm Bắc Mỹ (1981). Mỗi loài được xác định là chắc chắn ăn được, chắc chắn có độc, hoặc không rõ có thể ăn được và không được khuyến cáo. Lớp sau này được kết hợp với lớp độc. Hướng dẫn nêu rõ rằng không có quy tắc đơn giản nào để xác định khả năng ăn được của nấm; không có quy tắc như "tờ rơi ba, hãy để nó là" cho Pois độc Oak và Ivy.
- Nội dung Data
- Thuộc tính thông tin: (các lớp: ăn được = e, độc = p)
- hình nắp: chuông = b, hình nón = c, nhô = x, mũm = f, núm = k, trũng = s
- nắp mặt: sợi = f, rãnh = g, bay = y, gặt = s
- màu nắp: nâu = n, da bò = b, quế = c, xám = g, xanh lục = r, hồng = p, tím = u, đỏ = e, trắng = w, vàng = y
- Trace: thâm = t, không = f
- mùi: hạnh nhân = a, hồi = l, creosote = c, tanh = y, hôi = f, mốc = m, không = n, hăng = p, cay = s
- mang-đính kèm: gắn = a, giảm dần = d, tự do = f, khía = n
- khoảng cách mang: gần = c, đông đúc = w, xa = d
- mang size: width = b, chướng = n
- màu mang: đen = k, nâu = n, da bò = b, sô cô la = h, xám = g, xanh lá cây = r, cam = o, hồng = p, tím = u, đỏ = e, trắng = w, vàng = y
- cuống dạng: to ra = e, thon nhỏ = t
- gốc-cuống: củ = b, chùy = c, cốc = u, bằng = e, thân = z, gốc = r, thiếu =?
- bề mặt bề mặt-trên-vòng: sợi = f, dây = y, mượt = k, màn hình = s
- bề mặt bên dưới vòng: sợi = f, sợi = y, mượt = k, màn = s
- cuống-màu-trên-vòng: nâu = n, buff = b, quế = c, xám = g, cam = o, hồng = p, đỏ = e, trắng = w, vàng = y
- cuống-màu-dưới-vòng: nâu = n, buff = b, quế = c, xám = g, cam = o, hồng = p, đỏ = e, trắng = w, vàng = y
- Kiểu hình:một phần = p, tổng quát = u
- màu màn hình: nâu = n, cam = o, trắng = w, vàng = y
- số vòng: none = n, a = o, hai = t
- vòng loại: cobwebby = c, evanescent = e, loe = f, lớn = l, không = n, mặt dây = p, vỏ bọc = s, vùng = z
- spore-print-color: black = k, brown = n, buff = b, chocolate = h, green = r, cam = o, tím = u, trắng = w, vàng = y
- dân số: nhiều = a, nhóm = c, nhiều = n, rải rác = s, nhiều = v, đơn độc = y
- môi trường sống: cỏ = g, lá = l, đồng cỏ = m, đường đi = p, thành thị = u, chất màu = w, rừng = d
- Dữ liệu.
.png)
PHẦN II. TIỀN XỬ LÝ DATA.
PHẦN III. THUẬT TOÁN
- Giới thiệu và định nghĩa về thuật toán.
- SVM (Support Vector Machine) là một thuật toán học máy có giám sát được sử dụng rất phổ biến ngày nay trong các bài toán phân lớp (classification) hay hồi qui (Regression).
- SVM được đề xuất bởi Vladimir N. Vapnik và các đồng nhiệp của ông vào năm 1963 tại Nga và sau đó trở nên phổ biến trong những năm 90 nhờ ứng dụng giải quyết các bài toán phi tuyến tính (nonlinear) bằng phương pháp Kernel Trick.
- Support Vector Machine (SVM) là một thuật toán thuộc nhóm Supervised Learning (Học có giám sát) dùng để phân chia dữ liệu (Classification) thành các nhóm riêng biệt.
 SVM là một thuật toán giám sát, nó có thể sử dụng cho cả việc phân loại hoặc đệ quy. Tuy nhiên nó được sử dụng chủ yếu cho việc phân loại. Trong thuật toán này, chúng ta vẽ đồi thị dữ liệu là các điểm trong n chiều ( ở đây n là số lượng các tính năng bạn có) với giá trị của mỗi tính năng sẽ là một phần liên kết. Sau đó chúng ta thực hiện tìm "đường bay" phân chia các lớp. Đường bay - nó chỉ hiểu đơn giản là 1 đường thằng có thể phân chia các lớp ra thành hai phần riêng biệt.
SVM là một thuật toán giám sát, nó có thể sử dụng cho cả việc phân loại hoặc đệ quy. Tuy nhiên nó được sử dụng chủ yếu cho việc phân loại. Trong thuật toán này, chúng ta vẽ đồi thị dữ liệu là các điểm trong n chiều ( ở đây n là số lượng các tính năng bạn có) với giá trị của mỗi tính năng sẽ là một phần liên kết. Sau đó chúng ta thực hiện tìm "đường bay" phân chia các lớp. Đường bay - nó chỉ hiểu đơn giản là 1 đường thằng có thể phân chia các lớp ra thành hai phần riêng biệt.
2.Ý tưởng làm việc của thuật toán.
 - Ý tưởng của SVM là tìm một siêu phẳng (hyper lane) để phân tách các điểm dữ liệu. Siêu phẳng này sẽ chia không gian thành các miền khác nhau và mỗi miền sẽ chứa một loại giữ liệu.
- Ý tưởng của SVM là tìm một siêu phẳng (hyper lane) để phân tách các điểm dữ liệu. Siêu phẳng này sẽ chia không gian thành các miền khác nhau và mỗi miền sẽ chứa một loại giữ liệu.
Xét bài toán phân lớp đơn giản nhất
- Phân lớp hai lớp với tập dữ liệu mẫu:Trong đó mẫu là các vector đối tượng được phân lớp thành các mẫu dương và mẫuâm như trong hình.
- Các mẫu dương là các mẫu xi thuộc lĩnh vực quan tâm và được gán nhãn yi = 1.
- Các mẫu âm là các mẫu xi không thuộc lĩnh vực quan tâm và được gán yi = - 1
Thực chất phương pháp này là một bài toán tối ưu, mục tiêu là tìm ra một khônggian H và siêu mặt phẳng quyết định h trên H sao cho sai số phân lớp là thấp nhất.
Trong trường hợp này, tập phân lớp SVM là mặt siêu phẳng phân tách các mẫudương khỏi các mẫu âm với độ chênh lệch cực đại, trong đó độ chênh lệch – còn gọi là
Lề (margin) xác định bằng khoảng cách giữa các mẫu dương và các mẫu âm gần mặt siêuphẳng nhất. Mặt siêu phẳng này được gọi là mặt siêu phẳng lề tối ưu.
Tương đương với công thức
i=1,…,n
{(xi, yi) i = 1, 2,…, N, xi ∈ Rm }
C + w1 x1 + w2 x2 + … + wn xn = 0 (2.1)
C + ∑wi xi = 0 (2.2)
Với w = w1 + w2 + …+ wn là bộ hệ số siêu phẳng hay là vector trọng số, C là độ dịch, khithay đổi w và C thì hướng và khoảng cách từ gốc toạ độ đến mặt siêu phẳng thay đổi.
Tập phân lớp SVM được định nghĩa như sau:
f(x) = sign(C + ∑wi xi)
Trong đó
sign(z) = +1 nếu z ≥ 0,
sign(z) = -1 nếu z < 0.
Nếu f(x) = +1 thì x thuộc về lớp dương (lĩnh vực được quan tâm), và ngược lại,nếu f(x) = -1 thì x thuộc về lớp âm (các lĩnh vực khác).
Máy học SVM là một học các siêu phẳng phụ thuộc vào tham số vector trọng số wvà độ dịch C. Mục tiêu của phương pháp SVM là ước lượng w và C để cực đại hoá lềgiữa các lớp dữ liệu dương và âm. Các giá trị khác nhau của lề cho ta các họ siêu mặtphẳng khác nhau, và lề càng lớn thì năng lực của máy học càng giảm. Như vậy, cực đạihoá lề thực chất là việc tìm một máy học có năng lực nhỏ nhất. Quá trình phân lớp là tốiưu khi sai số phân lớp là cực tiểu.
Ta phải giải phương trình sau:tìm ra được vector trọng số w và sai số của mỗi điểm trong tập huấn luyện là ηi từ đó tacó phương trình tổng quát của siêu phẳng tìm ra được bởi thuật toán SVM là:
Với i = 1,…, n. Trong đó n là số dữ liệu huấn luyện.
Sau khi đã tìm được phương trình của siêu phẳng bằng thuật toán SVM, áp dụngcông thức này để tìm ra nhãn lớp cho các dữ liệu mới
3. Huấn luyện SVM
Huấn luyện SVM là việc giải bài toán quy hoạch toàn phương SVM. Các phương pháp số giải bài toán quy hoạch này yêu cầu phải lưu trữ một ma trận có kích thước bằng bình phương của số lượng mẫu huấn luyện. Trong những bài toán thực tế, điều này là không khả thi vì thông thường kích thước của tập dữ liệu huấn luyện thường rất lớn (có thể lên tới hàng chục nghìn mẫu). Nhiều thuật toán khác nhau được phát triển để giải quyết vấn đề nêu trên. Những thuật toán này dựa trên việc phân rã tập dữ liệu huấn luyện thành những nhóm dữ liệu. Điều đó có nghĩa là bài toán quy hoạch toàn phương với kích thước nhỏ hơn. Sau đó, những thuật toán này kiểm tra các điều kiện KKT (Karush-KuhnTucker) để xác định phương án tối ưu. Một số thuật toán huấn luyện dựa vào tính chất: Nếu trong tập dữ liệu huấn luyện của bài toán quy hoạch toàn phương con cần giải ở mỗi bước có ít nhất một mẫu vi phạm các điều kiện KKT, thì sau khi giải bài toán náy, hàm mục tiêu sẽ tăng. Như vậy, một chuỗi các bài toán quy hoạch toàn phương con với ít nhất một mẫu vi phạm các điều kiện KKT được đảm bảo hội tụ đến một phương án tối ưu. Do đó, ta có thể duy trì một tập dữ liệu làm việc đủ lớn có kích thước cố định và tại mỗi bước huấn luyện, ta loại bỏ và thêm vào cùng một số lượng mẫu.
PHẦN IV. CÁCH INPUT, OUTPUT DỮ LIỆU VÀO TRONG THUẬT TOÁN
Code train model
Code save model
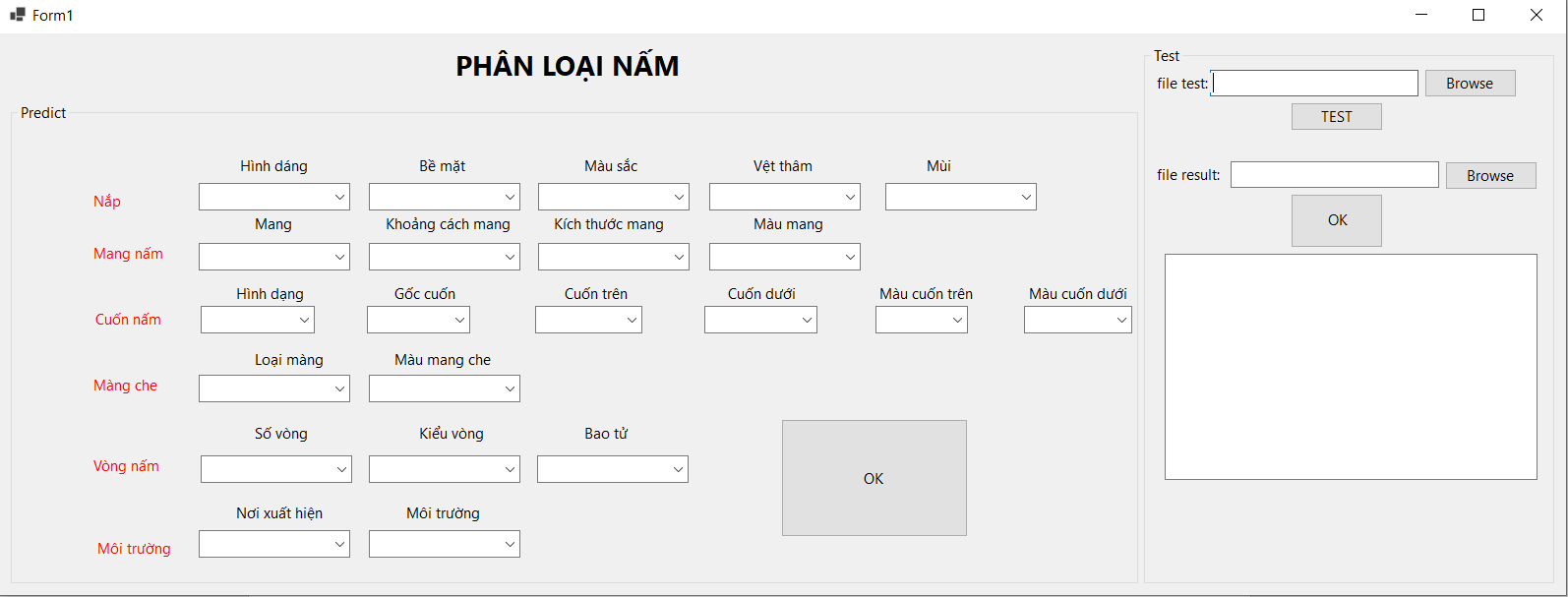
PHẦN V. GIAO DIỆN CHƯƠNG TRÌNH
.png)
Giao diện chương trình
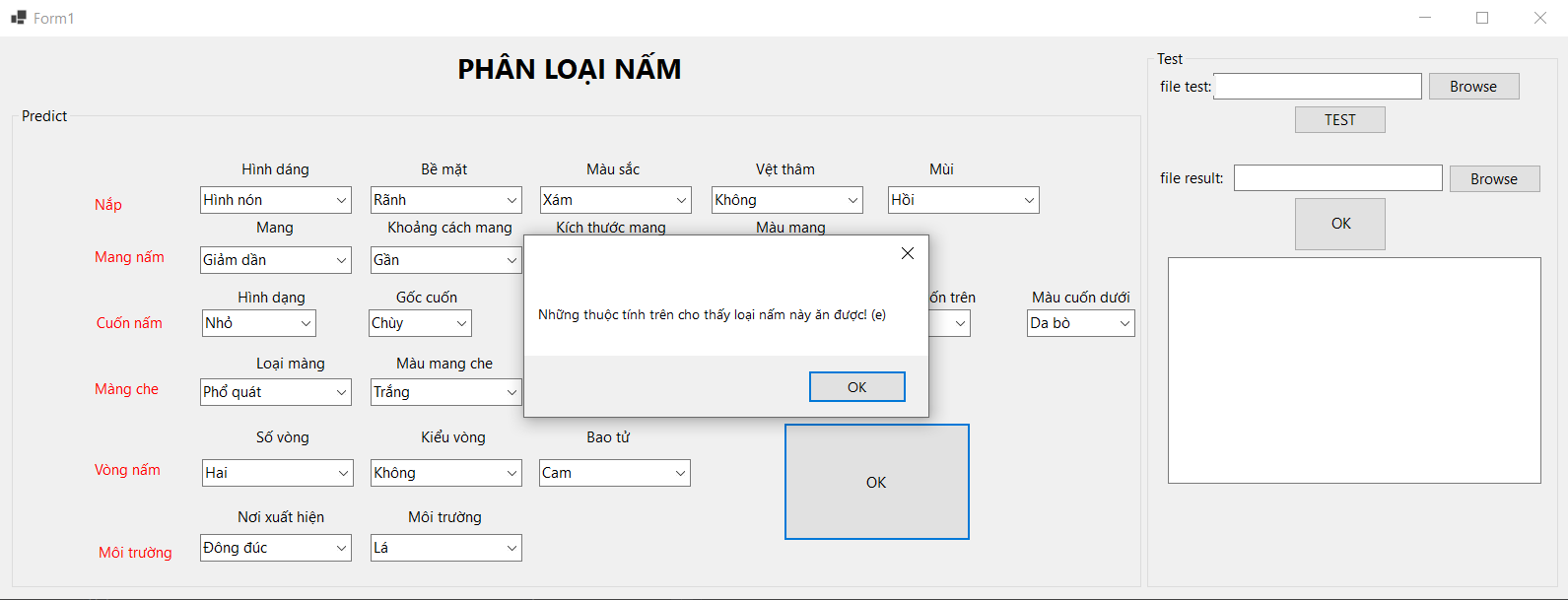
Người dùng chọn vào từng combox thuộc tính để đưa ra kết luận nấm không ăn được hoặc ăn được.
.png)
Phần predict của chương trình








")


/4.png "machinelearning-clustering-(gmm)")



")
.jpg "SVM (SUPPORT VECTORMACHINE)")

.jpg "PHƯƠNG PHÁP TẠO CÂY ĐỊNH DANH ID3")

























")




 trong deep learning")
 TRONG BÀI TOÁN KHAI THÁC TẬP LỢI ÍCH CAO")







