BOW; TF-IDF;ANN; KNN
- Khái niệm về BoW
- Mô hình túi từ (bag of words) là một biểu diễn đơn giản hóa được sử dụng trong xử lý ngôn ngữ tự nhiên và truy vấn thông tin. Trông mô hình này, một văn bản (một câu hoặc một tài liệu) được thể hiện dưới dạng túi chứa các từ của nó, không quan tâm đến ngữ pháp và thậm chí trật tự từ nhưng vẫn giữ tính đa dạng. Mô hình túi từ cũng đã được sử dụng cho thị giác máy tính.
- Mô hình túi từ thường được sử dụng trong các phương pháp phân loại tài liệu trong đó sự xuất hiện (tần suất) của mỗi từ được sử dụng như một đặc trưng để đào tạo máy phân loại.
- Mô hình túi từ là một cách trích xuất các tính năng từ văn bản để sử dụng trong mô hình hóa, chẳng hạn như với các thuật toán trong học máy (Machine Learning).
- Một quy trình trích xuất đặc điểm phổ biến cho các câu và tài liệu là phương pháp tiếp cận theo từng từ (BoW). Trong cách tiếp cận này, xem xét biểu đồ của các từ trong văn bản, tức là coi mối số từ là một đặc điểm.
- Khái niệm về TF-IDF
Term Frequency – Inverse Document Frequency viết tắt là tf-idf hay TF-IDF là một con số thu được thông qua thống kê thể hiện mức độ quan trọng của từ này trong một văn bản, mà vản thân văn bản đang xét nằm trong một tập hợp các văn bản đang xét nằ trong một tập hợp các văn bản. Giá trị tf-idf tăng tương ứng với số lần một từ xuất hiện trong tài liệu, nhưng thường được bù đắp bằng tần số của từ trong kho văn bản, giúp điều chỉnh thực tế là một số từ xuất hiện thường xuyên hơn nói chung. Giá trị TF-IDF của từ t đối với văn bản d trong tập văn bản D là:
Tfidf(t, d, D) = tf(t,d) * idf(t, D)
Với: - df(d, t): số lượng văn bản trong tập D có chứa từ t.
Những từ có giá trị TF-IDF cao là những từ xuất hiện nhiều trong văn này và xuất hiện ít trong văn bản khác. Việc này giúp lọc ra những từ phổ biến và giữ lại những từ có giá trị cao (từ khóa của văn bản đó).
- Khái niệm về Neural network
 Một cách ngắn gọn nhất thì Neural là mô hình toán học mô phỏng nơron trong hệ thống thần kinh con người. Model đó biểu hiện cho một số chức năng của nơron(neural) thần kinh con người.
Một cách ngắn gọn nhất thì Neural là mô hình toán học mô phỏng nơron trong hệ thống thần kinh con người. Model đó biểu hiện cho một số chức năng của nơron(neural) thần kinh con người.
Biểu đồ 3. 2. Biểu đồ mô hình dây thần kinh nơ ron
Tính chất truyền đi của thông tin trên neuron, khi neuron nhận tín hiệu đầu vào từ các dendrite, khi tín hiệu vượt qua một ngưỡng (threshold) thì tín hiệu sẽ được truyền đi sang neuron khác (Neurons Fire) theo sợi trục (axon). Neural của model toán học ở đây cũng được mô phỏng tương tự như vậy. Công thức tính output Y sẽ như sau:
y=a (w1x1 + w2x2 + w3x3 − θ) (1)
Với: y: tín hiệu output
x1, x2, x3: tín hiệu input
w1, w2, w3: weight
θ: ngưỡng threshold
a: activation function
Thực tế threshold trong phạm vi toán học có thể mang dấu (+) và (-), dựa trên công thức (1) đưa vào công thức bias: bias = b = - θ. Suy ra được công thức sau:
y=a (w1x1 + w2x2 + w3x3 + b) (2)
Với: b: bias
- Artificial Neural Network
Mạng nơ-ron nhân tạo (Artificial Neural Network – ANN) là một mô hình xử lý thông tin được mô phỏng dựa trên hoạt động của hệ thống thần kinh của sinh vật, bao gồm số lượng lớn các nơ-ron được gắn kết để xử lý thông tin. ANN hoạt động giống như bộ não của con người, được học bởi kinh nghiệm (thông qua việc huấn luyện), có khả năng lưu giữ các tri thức và sử dụng các tri thức đó trong việc dự đoán các dữ liệu chưa biết (unseen data).
Một mạng nơ-ron là một nhóm các nút nối với nhau, mô phỏng mạng nơ-ron thần kinh của não người. Mạng nơ-ron nhân tạo được thể hiện thông qua ba thành phần cơ bản: mô hình của nơ ron, cấu trúc và sự liên kết giữa các nơ ron. Trong nhiều trường hợp, mạng nơ-ron nhân tạo là một hệ thống thích ứng, tự thay đổi cấu trúc của mình dựa trên các thông tin bên ngoài hay bên trong chạy qua mạng trong quá trình học.
Sơ đồ 3. 1. Sơ đồ mạng nơ ron thần kinh
Kiến trúc chung của một ANN gồm 3 thành phần đó là Input Layer, Hidden Layer và Output Layer
Trong đó, lớp ẩn (Hidden Layer) gồm các nơ-ron, nhận dữ liệu input từ các nơ-ron ở lớp (Layer) trước đó và chuyển đổi các input này cho các lớp xử lý tiếp theo. Trong một mạng ANN có thể có nhiều Hidden Layer
Lợi thế lớn nhất của các mạng ANN là khả năng được sử dụng như một cơ chế xấp xỉ hàm tùy ý mà “học” được từ các dữ liệu quan sát. Tuy nhiên, sử dụng chúng không đơn giản như vậy, một số các đặc tính và kinh nghiệm khi thiết kế một mạng nơ-ron ANN.
Phương pháp này là tính toán tỷ lệ chính xác dữ liệu đầu ra (output) từ dữ liệu đầu vào (input) bằng cách tính toán các trọng số cho mỗi kết nối (connection) từ các lần lặp lại trong khi “huấn luyện” dữ liệu cho Chatbot. Mỗi bước “huấn luyện” dữ liệu cho Chatbot sẽ sửa đổi các trọng số dẫn đến dữ liệu output được xuất ra với độ chính xác cao.
- Chọn mô hình: Điều này phụ thuộc vào cách trình bày dữ liệu và các ứng dụng. Mô hình quá phức tạp có xu hướng dẫn đến những thách thức trong quá trình học.
- Cấu trúc và sự liên kết giữa các nơ-ron
- Thuật toán học: Có hai vấn đề cần học đối với mỗi mạng ANN, đó là học tham số của mô hình (parameter learning) và học cấu trúc (structure learning). Học tham số là thay đổi trọng số của các liên kết giữa các nơ-ron trong một mạng, còn học cấu trúc là việc điều chỉnh cấu trúc mạng bằng việc thay đổi số lớp ẩn, số nơ-ron mỗi lớp và cách liên kết giữa chúng. Hai vấn đề này có thể được thực hiện đồng thời hoặc tách biệt. Nếu các mô hình, hàm chi phí và thuật toán học được lựa chọn một cách thích hợp, thì mạng ANN sẽ cho kết quả có thể vô cùng mạnh mẽ và hiệu quả.

Inputs: Mỗi Input tương ứng với 1 đặc trưng của dữ liệu. Ví dụ như trong ứng dụng của ngân hàng xem xét có chấp nhận cho khách hàng vay tiền hay không thì mỗi input là một thuộc tính của khách hàng như thu nhập, nghề nghiệp, tuổi, số con,...
Output: Kết quả của một ANN là một giải pháp cho một vấn đề, ví dụ như với bài toán xem xét chấp nhận cho khách hàng vay tiền hay không thì output là yes hoặc no.
Connection Weights (Trọng số liên kết): Đây là thành phần rất quan trọng của một ANN, nó thể hiện mức độ quan trọng, độ mạnh của dữ liệu đầu vào đối với quá trình xử lý thông tin chuyển đổi dữ liệu từ layer này sang layer khác. Quá trình học của ANN thực ra là quá trình điều chỉnh các trọng số Weight của các dữ liệu đầu vào để có được kết quả mong muốn.
Summation Function (Hàm tổng): Tính tổng trọng số của tất cả các input được đưa vào mỗi nơ-ron. Hàm tổng của một nơ-ron đối với n input được tính theo công thức sau:
Y= i=1nXiWi
Transfer Function (Hàm chuyển đổi): Hàm tổng của một nơ-ron cho biết khả năng kích hoạt của nơ-ron đó còn gọi là kích hoạt bên trong. Các nơ-ron này có thể sinh ra một output hoặc không trong mạng ANN, nói cách khác rằng có thể output của một nơ-ron có thể được chuyển đến layer tiếp theo trong mạng nơ-ron hoặc không. Mối quan hệ giữa hàm tổng và kết quả output được thể hiện bằng hàm chuyển đổi.
Việc lựa chọn hàm chuyển đổi có tác động lớn đến kết quả đầu ra của mạng ANN. Hàm chuyển đổi phi tuyến được sử dụng phổ biến trong mạng ANN là sigmoid hoặc tanh.
fs= 11+e-s σ(s) 
tanhs= e5- e-5e5+ e-5
Trong đó, hàm tanh là phiên bản thay đổi tỉ lệ của sigmoid , tức là khoảng giá trị đầu ra của hàm chuyển đổi thuộc khoảng [-1, 1] thay vì [0,1] của Sigmoid nên chúng còn gọi là hàm chuẩn hóa (Normalized Function).
Kết quả xử lý tại các nơ-ron (Output) đôi khi rất lớn, vì vậy hàm chuyển đổi được sử dụng để xử lý output này trước khi chuyển đến layer tiếp theo. Đôi khi thay vì sử dụng Transfer Function người ta sử dụng giá trị ngưỡng (Threshold value) để kiểm soát các output của các nơ-ron tại một layer nào đó trước khi chuyển các output này đến các layer tiếp theo. Nếu output của một nơ-ron nào đó nhỏ hơn Threshold thì nó sẽ không được chuyển đến layer tiếp theo.
Mạng nơ-ron của chúng ta dự đoán dựa trên lan truyền thẳng (forward propagation) là các phép nhân ma trận cùng với activation function để thu được kết quả đầu ra. Nếu input x là vector 2 chiều thì ta có thể tính kết quả dự đoán y^ bằng công thức:
z1 = xW1 + b
a1 = tanh(z1)
z2 = a1W2 + b2
a2 = y^ = softmax(z2)
Trong đó, 𝑧𝑖 là input của layer thứ 𝑖, 𝑎𝑖 là output của layer thứ 𝑖 sau khi áp dụng activation function. 𝑊1, 𝑏1, 𝑊2, 𝑏2 là các tham số (parameters) cần tìm của mô hình mạng nơ-ron. Huấn luyện để tìm các tham số cho mô hình tương đương với việc tìm các tham số 𝑊1, 𝑏1, 𝑊2, 𝑏2 sao cho hàm lỗi của mô hình đạt được là thấp nhất. Ta gọi hàm lỗi của mô hình là loss function. Đối với softmax function, ta dùng crossentropy loss (còn gọi là negative log likelihood). Nếu ta có N ví dụ dữ liệu huấn luyện, và C nhóm phân lớp, khi đó hàm lỗi giữa giá trị dự đoán 𝑦^ và 𝑦 được tính:
Ly,y^= -1Nn∈ii∈Cyn.ilogyn,i^
Ý nghĩa công thức trên nghĩa là: lấy tổng trên toàn bộ tập huấn luyện và cộng dồn vào hàm loss nếu kết quả phân lớp sai. Độ dị biệt giữa hai giá trị 𝑦 và 𝑦 càng lớn thì độ lỗi càng cao. Mục tiêu của chúng ta là tối thiểu hóa hàm lỗi này. Ta có thể sử dụng phương pháp gradient descent để tối thiểu hóa hàm lỗi. Có hai loại gradient descent, một loại với fixed learning rate được gọi là batch gradient descent, loại còn lại có learning rate thay đổi theo quá trình huấn luyện được gọi là SGD (stochastic gradient descent) hay minibatch gradient descent.
Gradient descent cần các gradient là các vector có được bằng cách lấy đạo hàm của loss function theo từng tham số  để tính các gradient này, ta sử dụng thuật toán lan truyền ngược (backpropagation). Đây là cách hiệu quả để tính gradient khởi điểm từ output layer. [13]
để tính các gradient này, ta sử dụng thuật toán lan truyền ngược (backpropagation). Đây là cách hiệu quả để tính gradient khởi điểm từ output layer. [13]
Áp dụng giải thuật lan truyền ngược ta có các đại lượng:

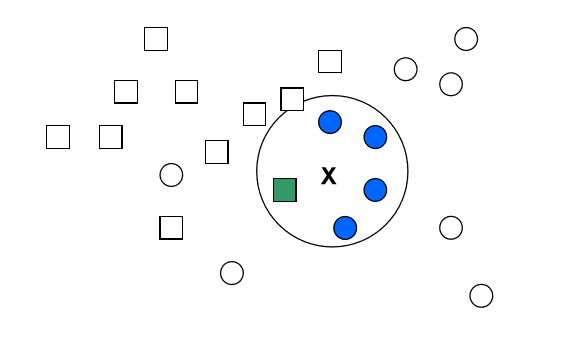
- Khái niệm về kNN
- K-Nearest Neighbor (kNN) là một trong những thuật toán học có giám sát đơn giản nhất trong Machine Learning. Ý tưởng của kNN là tìm ra output của dữ liệu dựa trên thông tin của những dữ liệu training gần nó nhất.
- Hoạt động của thuật toán kNN: Thuật toán K-láng giềng gần nhất (kNN) sử dụng “tính năng tương tự” để dự đoán giá trị của các điểm dữ liệu mới, điều này có nghĩa là điểm dữ liệu mới sẽ được chỉ định một giá trị dựa trên mức độ phù hợp chặt chẽ của nó với các điểm trong tập huấn luyện. Chúng tôi có thể hiểu cách hoạt động của nó với sự trợ giúp của các bước sau:
- Bước 1: Để thực hiện bất kỳ thuật toán nào, chúng ta cần tập dữ liệu. Vì vậy trong bước đầu tiên của kNN, chúng ta phải tải dữ liệu huấn luyện cũng như kiểm tra.
- Bước 2: Tiếp theo, chúng ta cần chọn giá trị của k tức là các điểm dữ liệu gần nhất. k có thể là bất kỳ số nguyên nào.
- Bước 3: Đối với mỗi điểm trong dữ liệu kiểm tra, hãy làm như sau:
- Tính toán khoảng cách giữa dữ liệu thử nghiệm và mỗi hàng dữ liệu huấn luyện với sự trợ giúp của bất kỳ phương pháp nào cụ thể là: Khoảng cách Euclidean, Manhattan hoặc Hamming. Phương pháp phổ biến nhất được sử dụng để tính khoảng cách là Euclidean.
- Bây giờ, dựa trên giá trị khoảng cách, hãy sắp xếp chúng theo thứ tự tăng dần.
- Tiếp theo, nó sẽ chọn K hàng trên cùng từ mảng đã sắp xếp.
- Bây giờ, nó sẽ chỉ định một lớp cho điểm kiểm tra dựa trên lớp thường xuyên nhất của các hàng này.
Việc tính toán khoảng cách giữa các đối tượng cần phân lớp với tất cả đối tượng trong tập dữ liệu huấn luyện thường được sử dụng với công thức tính khoảng cách Euclidean. Cho 2 điểm P1(x1, y1) và P2(x2, y2) thì khoảng cách Euclidean distance sẽ được tính theo công thức:
d=x2-x12+y2-y12
- Dễ sử dụng và cài đặt.
- Việc dự đoán kết quả của dữ liệu mới dễ dàng (sau khi đã xác định được các điểm lân cận).
- Độ phức tạp tính toán của quá trình huấn luyện là bằng 0.
- Không cần giả sử về phân phối của lớp.
- kNN nhiều dể đưa ra kết quả không chính xác khi k nhỏ.
Cần thời gian lưu training set, khi dữ liệu training và test tăng lên nhiều sẽ mất nhiều thời gian tính toán.


 ĐỂ DỰ ĐOÁN SỐ LIỆU HƯỚNG THỜI GIAN")


")

")
