- DEEP LEARNING
- Giới thiệu về Deep Learning
Deep learning[1] là một nhánh của lĩnh vực học máy, dựa trên một tập hợp các thuật toán nhằm cố gắng mô hình dữ liệu trừu tượng hóa ở mức cao bằng cách sử dụng nhiều lớp xử lý với cấu trúc phức tạp, hoặc bao gồm nhiều biến đổi phi tuyến.
Deep learning là một lớp của các thuật toán máy học:
- Sử dụng một tầng (cascade) nhiều lớp các đơn vị xử lý phi tuyến để trích trọn đặc trưng và chuyển đổi. Mỗi lớp kế tiếp dùng đầu ra từ lớp trước làm đầu vào. Thuật toán này có thể được giám sát hoặc không cần giám sát và được ứng dụng cho các mô hình phân tích (không có giám sát) và phân loại (giám sát).
- Dựa trên học (không có giám sát) của nhiều cấp các đặc trưng hoặc đại diện của dữ liệu. Các tính năng cao cấp bắt nguồn từ các tính năng thấp cấp hơn để tạo thành một đại diện thứ bậc.
- Là một phần của lĩnh vực máy học và rộng lớn hơn về việc học đại diện dữ liệu.
- Học nhiều cấp độ đại diện tương ứng với các mức độ trừu tượng khác nhau; các mức độ hình thành một hệ thống phân cấp của các khái niệm.
Deep learning còn là phương pháp nâng cao của mạng nơ-ron nhân tạo (Artificial Neural Networks) khai thác khả năng tính toán ngày càng rẻ từ các chip xử lý hiện đại. Phương pháp này nhắm tới việc xây dựng nhiều hơn các mạng nơ-ron phức tạp cũng như giải quyết bài toán semi-supervised do tập dữ liệu khổng lồ thường được gán nhãn không đầy đủ.
- Một số thuật toán Deep Learning
Deep learning có nhiều thuật toán khác nhau nên nó phát triển rất nhanh nhiều biến thể và thuật toán mới ra đời liên tục trong thời gian ngắn, có thể kể đến một số thuật toán như:
- Mạng nơ-ron sâu (DNN - Deep Nơ-ron Network)
- Mạng niềm tin sâu (Deep Belief Network)
- Mạng nơ-ron chập
- RNN
- LSTM
- Mạng nơ-ron nhân tạo (ANN)
Mạng nơ-ron nhân tạo[2] là một mô hình toán học hay mô hình tính toán được xây dựng dựa trên các mạng nơ-ron sinh học. Nó gồm có một nhóm các nơ-ron nhân tạo (nút) nối với nhau, và xử lý thông tin bằng cách truyền theo các kết nối và tính giá trị mới tại các nút.
ANN có một số ưu điểm nhưng một trong những ưu điểm nổi bật nhất là một thực tế là nó thực sự có thể học hỏi từ việc quan sát các tập dữ liệu. Theo cách này, ANN được sử dụng như một hàm ngẫu nhiên công cụ xấp xỉ. Các loại công cụ này giúp ước tính các phương pháp hiệu quả nhất về mặt chi phí và lý tưởng để đến các giải pháp trong khi xác định các chức năng tính toán hoặc phân phối. ANN lấy mẫu dữ liệu thay vì toàn bộ tập dữ liệu để đến các giải pháp, giúp tiết kiệm cả thời gian và tiền bạc. ANN được coi là các mô hình toán học khá đơn giản để nâng cao các công nghệ phân tích dữ liệu hiện có.
Có 2 loại nơ-ron nhân tạo chính là perceptron và sigmoid:
- Perceptron
Perceptron [3]được phát triển vào những năm 1950 và 1960 bởi nhà khoa học Frank Rosenblatt. Ngày nay, nó phổ biến trong nhiều mô hình mạng nơ-ron khác nhau. Một perceptron có một số đầu vào (input) nhị phân, 𝑥1, 𝑥2, ..., và tạo ra một đầu ra (output) nhị phân duy nhất.
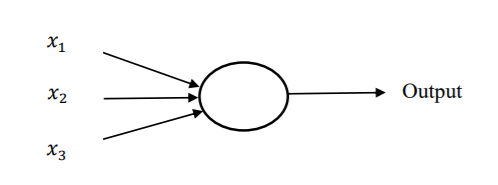
Hình 1.6 Một perceptron với ba đầu vào
Trong hình 1.6, Perceptron có ba đầu vào 𝑥1, 𝑥2, 𝑥3. Cũng có thể có nhiều hơn hoặc ít hơn số đầu vào. Rosenblatt đề xuất một quy tắc đơn giản để tính toán đầu ra. Các trọng số 𝑤1, 𝑤2, ... là các số thực thể hiện tầm quan trọng của các yếu tố đầu vào tương ứng với đầu ra.
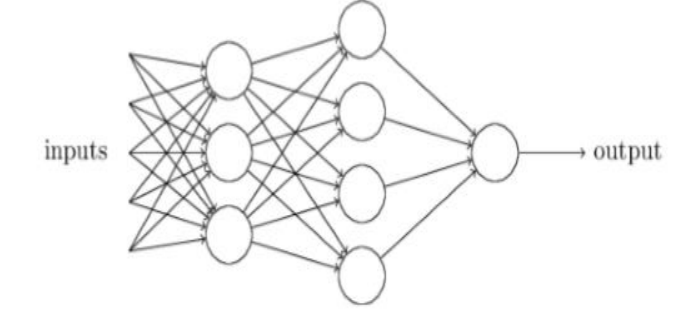
Hình 1.7 Mạng nơ-ron gồm nhiều perceptron
Trong hình 1.7, cột đầu tiên hay còn gọi là lớp đầu tiên của perceptron có thể đưa ra ba quyết định từ đầu vào. Còn trong lớp perceptron thứ hai, mỗi perceptron được quyết định bởi trọng số lên các đầu ra từ lớp đầu tiên. Perceptron trong lớp thứ hai có thể đưa ra quyết định ở mức độ phức tạp và trừu tượng hơn perceptron trong lớp đầu tiên. Và thậm chí quyết định phức tạp hơn có thể được thực hiện bởi các perceptron trong lớp thứ ba, thứ tư.... Bằng cách này, một mạng lưới nhiều lớp của perceptron có thể tham gia vào việc ra quyết định phức tạp.
Khi xác định perceptron thì một perceptron chỉ có một đầu ra duy nhất. Trong mạng trên, perceptron trông giống như có nhiều đầu ra nhưng thực ra chúng chỉ có một đầu ra. Việc nhiều mũi tên đầu ra chỉ là một cách hữu hiệu cho thấy đầu ra từ một perceptron đang được sử dụng như là đầu vào cho một vài perceptron khác.
- Sigmoid
Nơ-ron sigmoid tương tự như perceptron nhưng có sự sửa đổi để nếu có thay đổi nhỏ trong trọng số và định hướng chỉ gây ra một sự thay đổi nhỏ trong đầu ra. Đây là điều rất quan trọng cho phép một mạng lưới các nơ-ron sigmoid có thể học.
-
-
- Kiến trúc ANN:
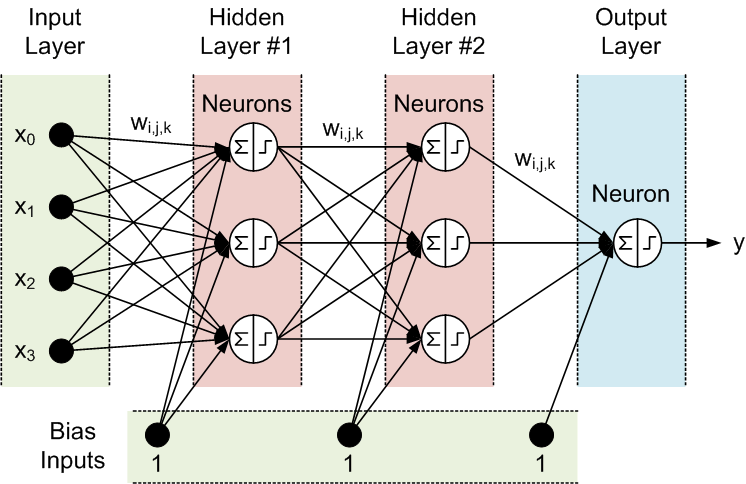
ANN thường có ba lớp được kết nối với nhau. Lớp đầu tiên bao gồm các nơron đầu vào. Những nơron này gửi dữ liệu lên lớp thứ hai, và nó sẽ gửi các nơron đầu ra tới lớp thứ ba:
- Lớp đầu vào: lớp này lấy khối lượng lớn dữ liệu đầu vào dưới dạng văn bản, số, tệp âm thanh, pixel hình ảnh, ...
- Lớp ẩn: có trách nhiệm thực hiện phép toán, phân tích mẫu, trích xuất đối tượng, … Một ANN có thể có nhiều lớp ẩn.
- Lớp đầu ra: chịu trách nhiệm tạo ra kết quả mong muốn.
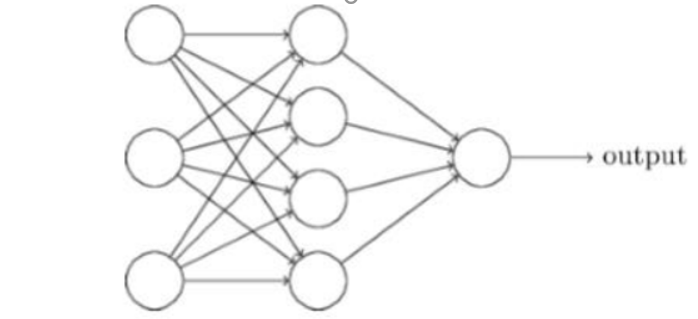
Hình 1.8 Mạng Nơ ron một lớp ẩn
Hình 1.8 đây là mạng nơ-ron đơn giản với một lớp ẩn, lớp ngoài cùng bên trái trong mạng này được gọi là lớp đầu vào, và các nơ-ron trong lớp này được gọi là nơ-ron đầu vào. Lớp ngoài cùng bên phải hoặc đầu ra chứa các nơ-ron đầu ra, như trong trường hợp này chỉ có một nơron đầu ra duy nhất. Lớp giữa được gọi là lớp ẩn, các nơ-ron trong lớp này không phải đầu vào cũng không đầu ra.
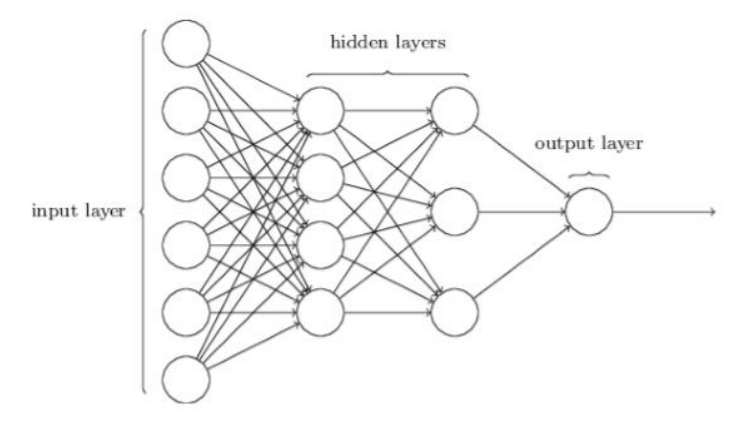
Hình 1.9 Mạng Nơ ron hai lớp ẩn
Trong khi việc thiết lập lớp đầu vào và đầu ra của một mạng nơ-ron thường đơn giản, thì việc tạo các lớp ẩn thường mất nhiều thời gian và công sức. Do đó, các nhà nghiên cứu mạng nơ-ron đã phát triển nhiều công nghệ tự động thiết kế cho các lớp ẩn, giúp mọi người có được những đầu ra theo hướng mình mong muốn. Điều này có thể được sử dụng để cân bằng số lớp ẩn với thời gian cần thiết để đào tạo mạng.
-
-
- Quá trình xử lý thông tin của một ANN:

Hình 1.10 Quá trình xử lý thông tin của một ANN
Inputs: Mỗi Input tương ứng với 1 thuộc tính (attribute) của dữ liệu (patterns).
Output: Kết quả của một ANN là một giải pháp cho một vấn đề cụ thể.
Connection Weights (Trọng số liên kết): Đây là thành phần rất quan trọng của một ANN, nó thể hiện mức độ quan trọng (độ mạnh) của dữ liệu đầu vào đối với quá trình xử lý thông tin (quá trình chuyển đổi dữ liệu từ Layer này sang layer khác). Quá trình học (Learning Processing) của ANN thực ra là quá trình điều chỉnh các trọng số (Weight) của các input data để có được kết quả mong muốn.
Summation Function (Hàm tổng): Tính tổng trọng số của tất cả các input được đưa vào mỗi Neuron (phần tử xử lý PE). Hàm tổng của một nơ-ron cho biết khả năng kích hoạt (Activation) của nơron đó còn gọi là nội kích hoạt (Internal Activation)
-
-
- Quá trình học của một ANN:
ANN được huấn luyện (Training) hay được học (Learning) theo 2 kỹ thuật cơ bản đó là học có giám sát (Supervised Learning) và học không giám sát (Unsupervised Learning).
Supervised learning: Quá trình Training được lặp lại cho đến kết quả (output) của ANN đạt được giá trị mong muốn (Desired value) đã biết. Điển hình cho kỹ thuật này là mạng Neuron lan truyền ngược (Backpropagation).
Unsupervised learning: Không sử dụng tri thức bên ngoài trong quá trình học (Learning), nên còn gọi là tự tổ chức (Self – Organizing). Mạng Neuron điển hình được huấn luyện theo kiểu Unsupervised là Sefl – Organizing Map (SOM).
- MẠNG NÔRON HỒI QUY RNN
- Mạng hồi quy RNN là gì?
Ý tưởng chính của RNN (Recurrent Neural Network) là sử dụng chuỗi các thông tin. Trong các mạng nơ-ron truyền thống tất cả các đầu vào và cả đầu ra là độc lập với nhau. Tức là chúng không liên kết thành chuỗi với nhau. Nhưng các mô hình này không phù hợp trong rất nhiều bài toán. Ví dụ, nếu muốn đoán từ tiếp theo có thể xuất hiện trong một câu thì ta cũng cần biết các từ trước đó xuất hiện lần lượt thế nào chứ nhỉ? RNN được gọi là hồi quy (Recurrent) bởi lẽ chúng thực hiện cùng một tác vụ cho tất cả các phần tử của một chuỗi với đầu ra phụ thuộc vào cả các phép tính trước đó. Nói cách khác, RNN có khả năng nhớ các thông tin được tính toán trước đó. Trên lý thuyết, RNN có thể sử dụng được thông tin của một văn bản rất dài, tuy nhiên thực tế thì nó chỉ có thể nhớ được một vài bước trước đó mà thôi.
Để có thể hiểu rõ về RNN, trước tiên chúng ta cùng nhìn lại mô hình Neural Network dưới đây:
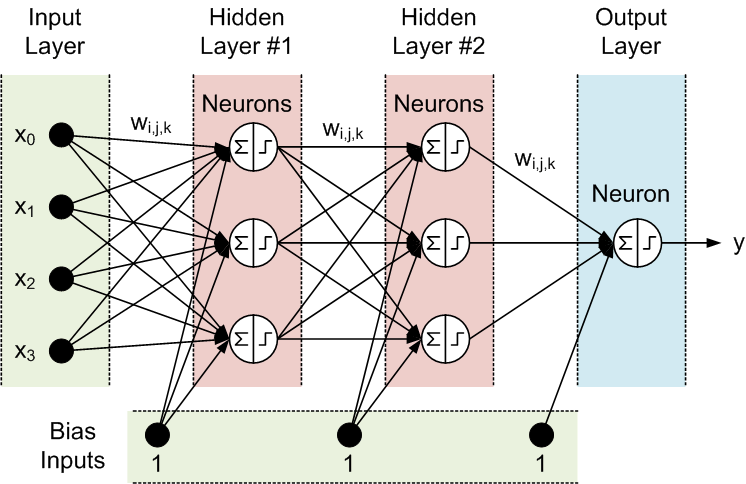
Hình 1.11 Mô hình kiến trúc Neural Network
Như đã biết thì Neural Network bao gồm 3 phần chính là Input layer, Hidden layer và Output layer, ta có thể thấy là đầu vào và đầu ra của mạng neuron này là độc lập với nhau. Như vậy mô hình này không phù hợp với những bài toán dạng chuỗi như mô tả, hoàn thành câu, ... vì những dự đoán tiếp theo như từ tiếp theo phụ thuộc vào vị trí của nó trong câu và những từ đằng trước nó.
- Kiến trúc của một mạng RNN truyền thống
Các mạng neural hồi quy, còn được biến đến như là RNNs, là một lớp của mạng neural cho phép đầu ra được sử dụng như đầu vào trong khi có các trạng thái ẩn. Thông thường là như sau:
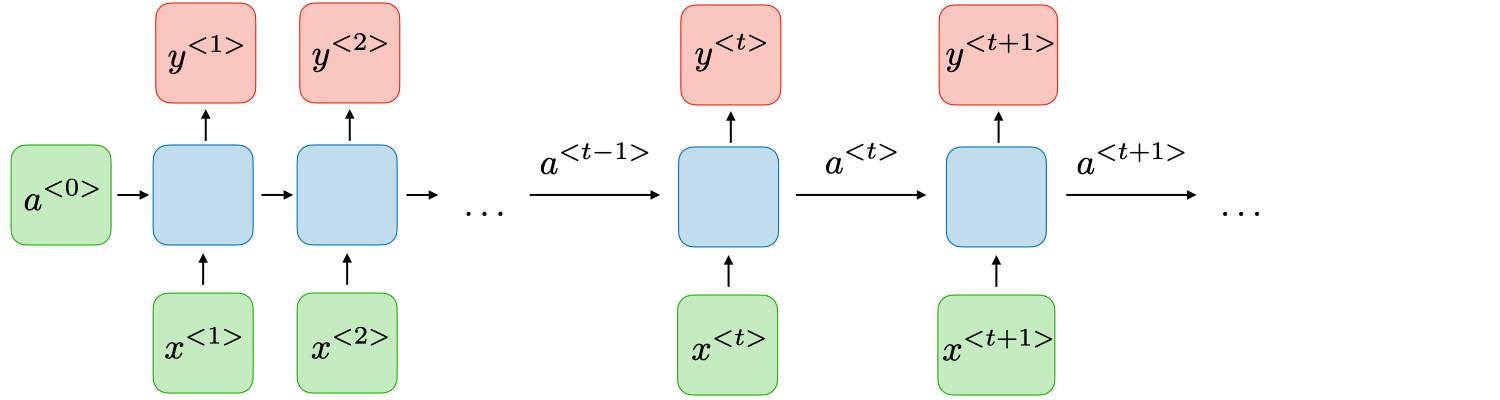
Hình 1.12 Mô hình kiến trúc RNN
Tại mỗi bước t, giá trị kích hoạt a< t > và đầu ra y< t > được biểu diễn như sau:
a< t >=g1*(Waa * a< t-1 > + Wax * x< t > + ba)
y< t >=g2*(Wya * a< t > + by)
với Wax, Waa, Wya, ba, by là các hệ số được chia sẻ tạm thời và g1, g2 là các hàm kích hoạt.

Ưu và nhược điểm của một kiến trúc RNN thông thường được tổng kết ở bảng dưới đây:
|
Ưu điểm
|
Hạn chế
|
|
• Khả năng xử lí đầu vào với bất kì độ dài nào
• Kích cỡ mô hình không tăng theo kích cỡ đầu vào
• Quá trình tính toán sử dụng các thông tin cũ
• Trọng số được chia sẻ trong suốt thời gian
|
• Tính toán chậm
• Khó để truy cập các thông tin từ một khoảng thời gian dài trước đây
• Không thể xem xét bất kì đầu vào sau này nào cho trạng thái hiện tại
|
- Ứng dụng của RNNs
Các mô hình RNN hầu như được sử dụng trong lĩnh vực xử lí ngôn ngữ tự nhiên và ghi nhận tiếng nói. Các ứng dụng khác được tổng kết trong bảng dưới đây:
|
Các loại RNN
|
Hình minh hoạ
|
Ví dụ
|
|
Một-Một
Tx=Ty=1
|

|
Mạng neural truyền thống
|
|
Một-nhiều
Tx=1, Ty>1
|
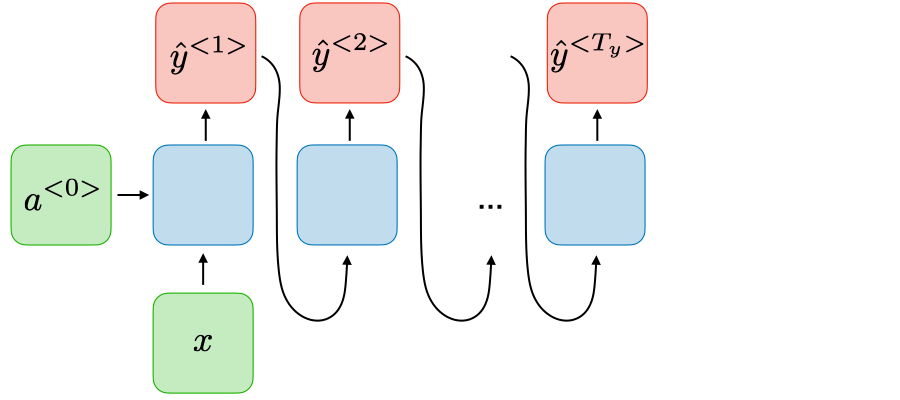
|
Sinh nhạc
|
|
Nhiều-một
Tx>1, Tx=1
|
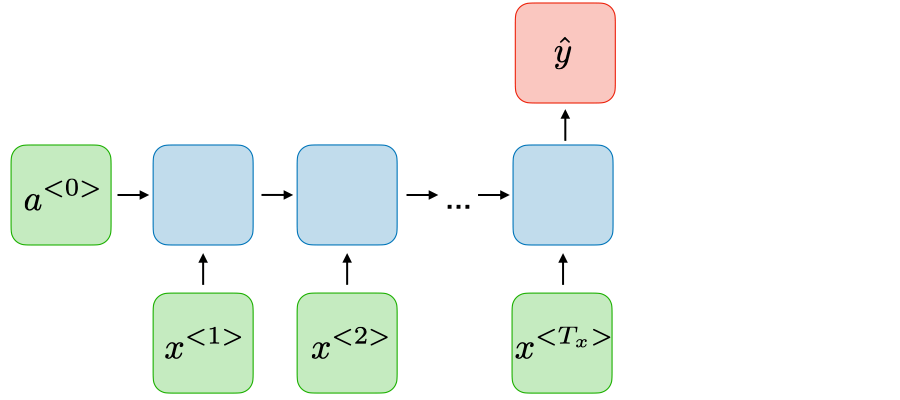
|
Phân loại ý kiến
|
|
Nhiều-nhiều
Tx=Ty
|
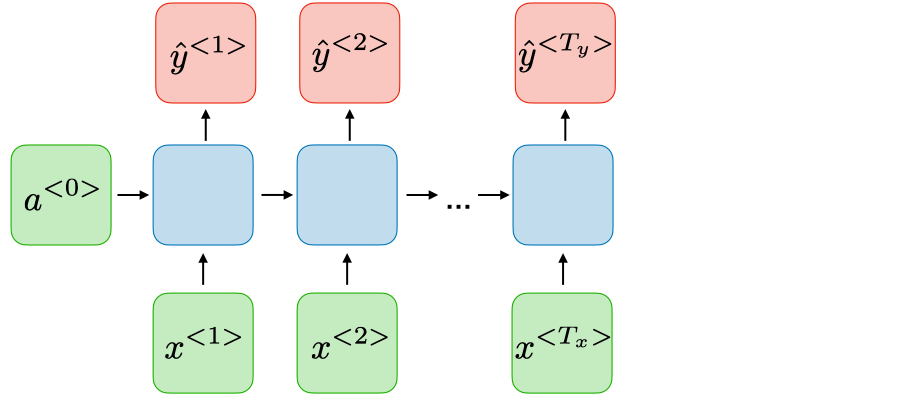
|
Ghi nhận thực thể tên
|
|
Nhiều-nhiều
Tx ≠ Ty
|

|
Dịch máy
|
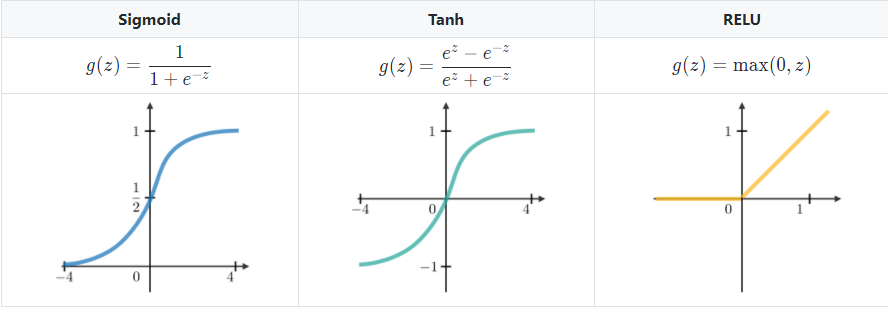
- Các hàm kích hoạt thường dùng (g1,g2)
Các hàm kích hoạt thường dùng trong các modules RNN được miêu tả như sau:
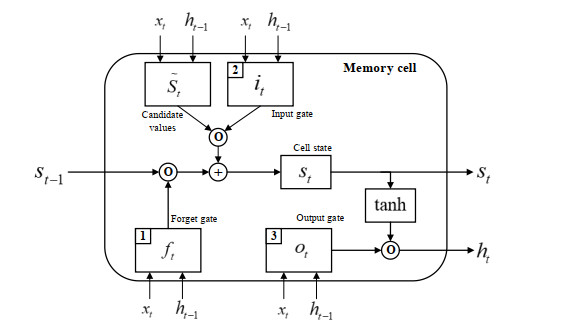
- LSTM
LSTM là một phiên bản mở rộng của mạng Recurrent Neural Network (RNN), nó được thiết kế để giải quyết các bài toán về phụ thuộc xa (long-term dependencies). RNN là mạng nơ-ron có chứa vòng lặp. Mạng này có khả năng lưu trữ thông tin, thông tin được
truyền từ lớp này sang lớp khác. Đầu ra của lớp ẩn phụ thuộc vào thông tin của các lớp tại mọi thời điểm. RNN đã được sử dụng phổ biến trong xử lý ngôn ngữ tự nhiên hay các bài toán có dữ liệu tuần tự. Tuy nhiên, do kiến trúc của RNN khá đơn giản nên khả năng lien kết các lớp có khoảng cách xa là không tốt. Nó cơ bản không có khả năng ghi nhớ thông tin từ các dữ liệu có khoảng cách xa, và do đó, những phần tử đầu tiên trong chuỗi đầu vào thường không có nhiều ảnh hưởng đến kết quả dự đoán phần tử cho chuỗi đầu ra các bước sau. Nguyên nhân của việc này là do RNN chịu ảnh hưởng bởi việc đạo hàm bị thấp dần trong quá trình học – biến mất đạo hàm (vanishing gradient). Mạng LSTM được thiết kế để khắc phục vấn đề này. Cơ chế hoạt động của LSTM là chỉ ghi nhớ những thông tin liên quan, quan trọng cho việc dự đoán, còn các thông tin khác sẽ được bỏ đi.
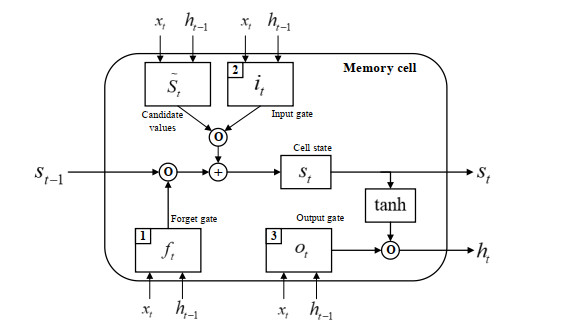
Hình 1.6 Mô hình LSTM
Mạng LSTM có thể bao gồm nhiều tế bào LSTM liên kết với nhau. Ý tưởng của LSTM
là bổ sung thêm trạng thái bên trong tế bào (cell internal state) 𝑠𝑡 và ba cổng sàng lọc
thông tin đầu vào và đầu ra cho tế bào bao gồm cổng quên 𝑓𝑡, cổng đầu vào 𝑖𝑡 và cổng đầu ra 𝑜𝑡. Tại mỗi bước thời gian t, các cổng lần lượt nhận giá trị đầu vào 𝑥𝑡 (đại diện cho một phần tử trong chuỗi đầu vào) và giá trị ℎ𝑡-1 có được từ đầu ra của các ô nhớ từ bước thời gian trước đó t – 1. Các cổng đều có chức năng sàng lọc thông tin với mỗi mục đích khác nhau. Các cổng được định nghĩa như sau:
Cổng quên: Có chức năng loại bỏ những thông tin không cần thiết nhận được khỏi
trạng thái tế bào bên trong.
Cổng đầu vào: Giúp sàng lọc những thông tin cần thiết để được thêm vào trạng thái tế
bào bên trong.
Cổng đầu ra: Có chức năng xác định những thông tin nào từ các trạng thái tế bào bên trong được sử dụng như đầu ra.
Trong quá trình thực hiện, 𝑠𝑡 và các giá trị đầu ra ℎ𝑡 được tính toán như sau:
Ở bước đầu tiên, tế bào LSTM quyết định những thông tin cần được loại bỏ từ các trạng thái tế bào bên trong ở bước thời gian trước đó 𝑠𝑡-1. Giá trị 𝑓𝑡 của cổng quên tại bước thời gian t được tính toán dựa trên giá trị đầu vào hiện tại 𝑥𝑡, giá trị đầu ra ℎ𝑡-1 từ tế bào LSTM ở bước trước đó và độ lệch (bias) 𝑏𝑓 của cổng quên. Hàm sigmoid biến đổi tất cả các giá trị kích hoạt (activation value) về miền giá trị trong khoảng từ 0 và 1 theo công thức:
𝑓𝑡 = 𝜎(𝑊𝑓,𝑥𝑥𝑡 + 𝑊𝑓,ℎℎ𝑡-1 + 𝑏𝑓)
Ở bước thứ 2, tế bào LSTM xác định những thông tin nào cần được thêm vào các trạng thái tế bào bên trong 𝑠𝑡. Bước này bao gồm hai quá trình tính toán đối với 𝑠𝑡 và 𝑓𝑡. 𝑠𝑡 biểu diễn những thông tin có thể được thêm vào các trạng thái tế bào bên trong:
𝑠𝑡 = 𝑡𝑎𝑛ℎ(𝑊𝑠,𝑥𝑥𝑡 + 𝑊𝑠,ℎℎ𝑡-1 + 𝑏𝑠)
Giá trị 𝑖𝑡 của cổng đầu vào tại bước thời gian t được tính:
𝑖𝑡 = 𝜎(𝑊𝑖,𝑥𝑥𝑡 + 𝑊𝑖,ℎℎ𝑡-1 + 𝑏𝑖)
Ở bước tiếp theo, giá trị mới của trạng thái tế bào bên trong 𝑠𝑡 được tính toán dựa trên kết quả thu được từ các bước trên:
𝑠𝑡 = 𝑓𝑡 ∗ 𝑠𝑡-1 + 𝑖𝑡 ∗ 𝑠𝑡
Cuối cùng, giá trị đầu ra ℎ𝑡:
𝑜𝑡 = 𝜎(𝑊𝑜,𝑥𝑥𝑡 + 𝑊𝑜,ℎℎ𝑡-1 + 𝑏𝑜)
ℎ𝑡 = 𝑜𝑡 ∗ 𝑡𝑎𝑛ℎ(𝑠𝑡)
Trong đó:
𝑊𝑠 ,𝑥, 𝑊𝑠,ℎ, 𝑊𝑓,𝑥, 𝑊𝑓,ℎ, 𝑊𝑖,𝑥, 𝑊𝑖,ℎ là các ma trận trọng số trong mỗi tế bào LSTM. 𝑏𝑓 , 𝑏𝑠, 𝑏𝑖, 𝑏𝑜 là các vector bias.
-
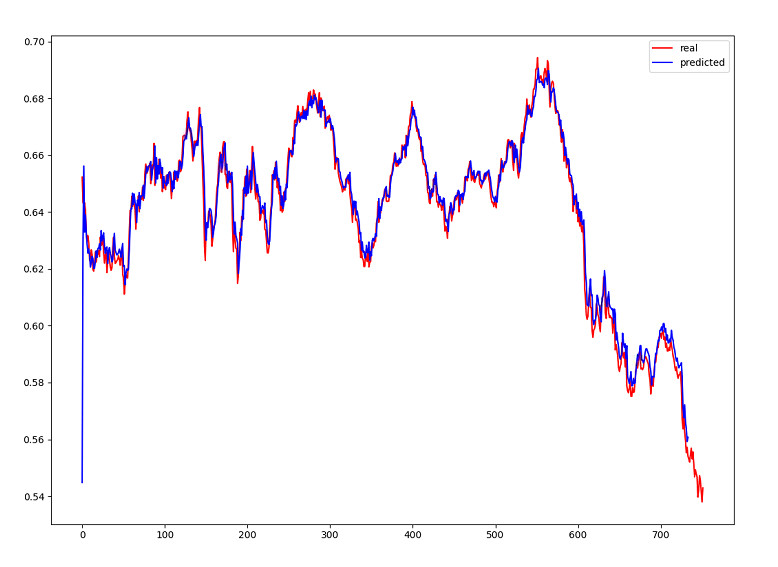
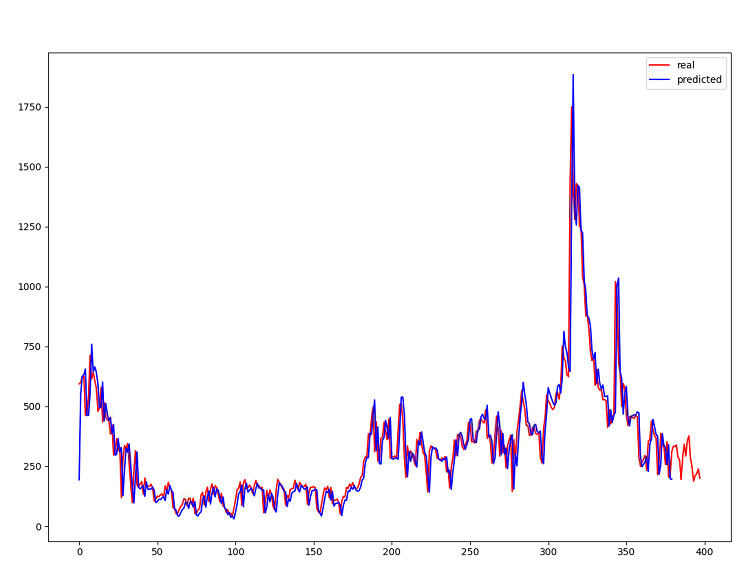
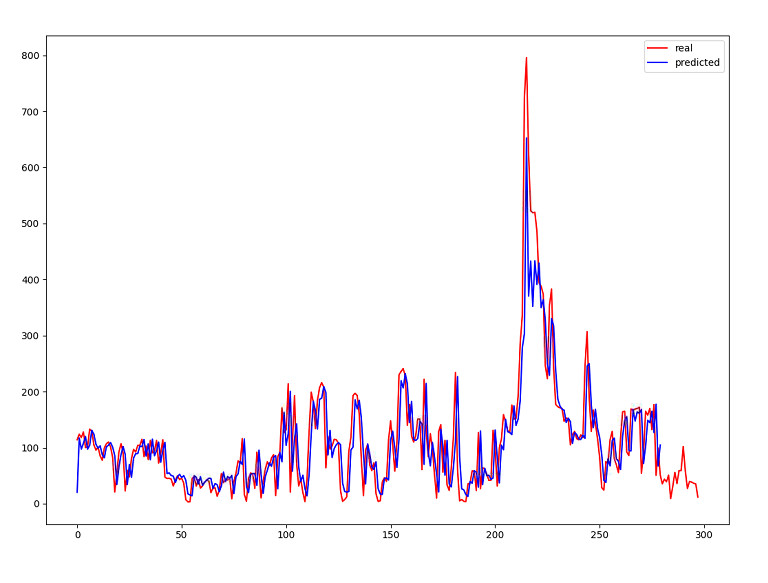
KẾT QUẢ THỰC NGHIỆM
|
Tên DataSet
|
Số lượng training
|
Số lượng test
|
LSTM & Chaotic TimeSeries
|
|
1983-2013_7548
|
6794
MAE: 0.0293
MSE: 1.7232e-04
|
754
|
MAE: 0.0123
MSE: 3.3251e-04
|
|
runoff_3000
|
2700
MAE: 0.0042
MSE: 2.0729e-05
|
300
|
MAE: 0.0109
MSE: 8.1871e-04
|
|
runoff_4000
|
3600
MAE: 0.0333
MSE: 0.0010
|
400
|
MAE: 0.0131
MSE: 9.3748e-04
|
|
Tên DataSet
|
Số lượng training
|
Số lượng test
|
LSTM & Chaotic TimeSeries
|
|
AUD-GBP -
|
5283
MAE:
MSE:
|
528
|
2265
MAE:
MSE:
|
|
runoff_3000_
|
2700
MAE:
MSE:
|
300
|
MAE:
MSE:
|
|
runoff_4000_
|
3600
MAE:
MSE:
|
400
|
MAE:
MSE:
|
.png)
.png)
.png)
- Biết được tổng quan về các khái niệm của Tensorflow, cách thức hoạt động và áp dụng thực tế vào dự báo dữ liệu hướng thời gian.
- Các phương pháp học thường được sử dụng trong học máy trong đó tập trung vào tìm hiểu và nghiên cứu về bài toán thuộc phương pháp học có giám sát.
- Tìm hiểu về khái niệm, một số thuật toán của Deep Learning.
- Nghiên cứu tập trung về cấu trúc và hoạt động của một mô hình mạng cụ thể: Mạng nơ ron nhân tạo ANN, CNN, LSTM.
- Nghiên cứu vận dụng được Chaotic TimeSeries vào thuật toán LSTM.
- Tìm hiểu các phương pháp huấn luyện cơ bản, thông dụng hiện nay.
- Tìm hiểu về cấu trúc và cách thức sử dụng ngôn ngữ lập trình Python, thư viện Tensorflow, và một số công cụ khác.
- Nhóm đã xây dựng được model dự báo dữ liệu hướng thời gian tương đối hoàn chỉnh có định danh sử dụng ngôn ngữ Python cũng như thư viện Tensorflow, Keras.
- Hoàn thành xây dựng model và kiểm thử trên 03 bộ dataset với kết quả tốt.






")

")
