HỆ THỐNG HỖ TRỢ TƯ VẤN
Xây dựng hệ thống trả lời tự động tư vấn tuyển sinh bằng phương pháp tìm kiếm thông tin văn bản dựa vào: biểu thức chính quy và mô hình túi từ để trả về những câu hỏi tương đồng cho các câu hỏi của thí sinh về tư vấn tuyển sinh một cách nhanh chóng và kịp thời.
Hai phương pháp tìm kiếm này sẽ hỗ trợ cho nhau trả về các câu trả lời tương đồng cho thí sinh, để các em có những thông tin nhu cầu của mình.
Để đạt được mục tiêu trên, tôi tiến hành nghiên cứu đề xuất giải pháp tìm hiểu về tìm kiếm theo biểu thức chính quy và tìm kiếm theo mô hình túi từ xây dựng một website để minh họa cho giải pháp đề xuất.
- Tìm hiểu về tư vấn tuyển sinh và thắc mắc về nhu cầu chọn ngành của thí sinh.
- Nghiên cứu cơ sở lý thuyết về hệ thống tìm kiếm thông tin văn bản, biểu thức chính quy, mô hình túi từ và giải thuật máy học kNN, BOW, LSI
Đối tượng nghiên cứu của đề tài là cơ sở lý thuyểt về tìm kiếm thông tin văn bản, biểu thức chính quy, mô hình túi từ, giải thuật máy học kNN, độ đo cosine, độ chính xác Precision at K, hoạt động tư vấn tuyển sinh tại trường,…
Trong khuôn khổ của luận văn, tôi tập trung nghiên cứu các nội dung sau:
- Tìm hiều về hệ thống tìm kiếm thông tin văn bản.
- Tìm hiểu và sử dụng mô hình túi từ dựa vào mô hình túi từ trong việc biểu diễn dữ liệu văn bản.
- Tìm hiểu và sử dụng độ đo cosine trong xác định tài liệu tương đồng.
- Tìm hiểu và sử dụng phương pháp k láng giềng, biểu thức chính quy.
- Tìm hiểu và sử dụng độ chính xác Precision at K để đánh giá hệ thống.
Để đạt được những yêu cầu trên, tôi sử dụng chủ yếu hai phương pháp chính là phương pháp nghiên cứu tài liệu và phương pháp thực nghiệm.
Phương pháp nghiên cứu tài liệu: tôi sử dụng phương pháp này trong nghiên cứu các tài liệu về cơ sở lý thuyết: tìm kiếm thông tin văn bản, tiền xử lý dữ liệu, mô hình túi từ, giải thuật máy học kNN, biểu thức chính quy; thu thập tài liệu từ nhiều nguồn khác nhau: các bài báo, các đề tài nghiên cứu, khóa luận tốt nghiệp được đánh giá cao và những tài liệu khác có liên quan đến những vấn đề này nhằm đưa ra những thông tin cần thiết phục vụ nghiên cứu.
Phương pháp thực nghiệm: phương pháp này được tôi sử dụng để khảo sát tình hình tư vấn tuyển sinh (TVTS). Thu thập dữ liệu câu hỏi – câu trả lời thường gặp, tôi tiến hành phân tích các hiện trạng, các yêu cầu thực tế của bài toán và xây dựng các bước phân tích hệ thống để hỗ trợ việc lập trình, xây dựng ứng dụng, đánh giá kết quả đạt được.
Báo cáo của luận văn được tổ chức thành 5 chương chính như sau:
Chương 1: Tổng quan: trình bày tổng quan về tìm kiếm thông tin và hệ thống tìm kiếm thông tin.
Chương 2: Cơ sở lý thuyết làm nền tảng để xây dựng ứng dụng, bao gồm những nội dung: trình bày lý thuyết tìm kiếm thông tin, một số vấn đề liên quan lý thuyết vector và ma trận, lý thuyết mô hình túi từ, độ đo cosine, giải thuật máy học kNN, LSI, BOW, biểu thức chính quy, độ chính xác, phương pháp đánh giá và kết quả.
Chương 3: Hệ thống trả lời tự động: cài đặt thực nghiệm: thu thập dữ liệu, trình bày quy trình của hệ thống, tập dữ liệu, trích đặc trưng, bộ truy vấn đánh giá và cài đặt chi tiết, đánh giá kết quả.
Chương 4: Kết quả thực nghiệm.
Chương 5: Kết luận.
CHƯƠNG 3: CÀI ĐẶT HỆ THỐNG
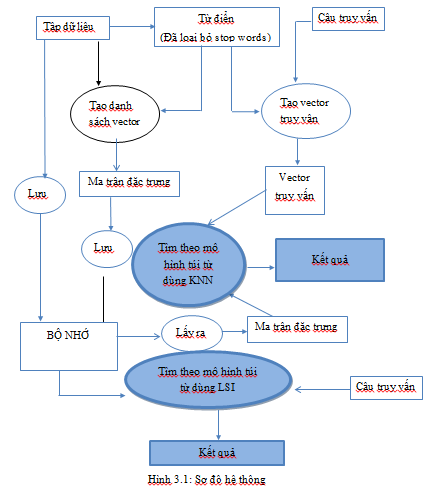
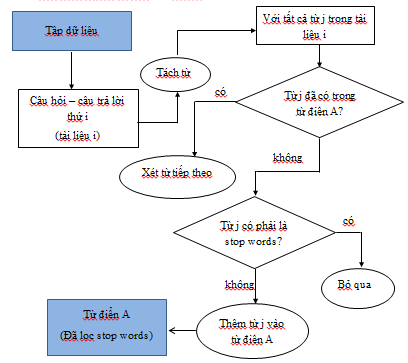
Hình 3.1: Sơ đồ hệ thống
Quy trình hệ thống trả lời tự động tư vấn bảo hiểm xã hội được mô tả như sau:
Từ tập dữ liệu thực hiện phương pháp tách từ đơn đồng thời loại bỏ các stop words để xây dựng từ điển, từng tài liệu (câu hỏi) trong tập dữ liệu được kết hợp với từ điển đã được loại bỏ stop words để vector hóa tập dữ liệu tạo ra danh sách các vector. Tập dữ liệu, từ điển và danh sách các vector đặc trưng được lưu trữ.
Nếu người dùng chọn phương pháp tìm kiếm bằng mô hình túi từ thì câu truy vấn sẽ được vector hóa, sau đó hệ thống thực hiện quá trình tính toán độ tương đồng giữa vector câu truy vấn với danh sách các vector trong cơ sở dữ liệu. Kết quả tính toán được hệ thống sắp xếp theo chiều giảm dần của độ tương đồng, k tài liệu tương ứng với k vector đặc trưng có độ tương đồng cao nhất được chọn để trả về cho người dùng.
Tập dữ liệu được sử dụng trong đề tài gồm có 500 cặp câu hỏi - câu trả lời, được sưu tập từ dữ liệu bảo hiểm xã hội và tham khảo từ tình hình tư vấn bảo hiểm xã hội của Tỉnh. Nội dung trong tập dữ liệu là những vấn đề liên quan đến thông tin bảo hiểm xã hội
Tập dữ liệu được sử dụng trong đề tài là Tiếng việt có dấu. Các cặp câu hỏi - câu trả lời có độ dài ngắn khác nhau và có cấu trúc không đồng nhất. Số lượng tài liệu tương đồng với nhau trong mỗi nội dung là không cố định, có nội dung chỉ gồm một, hai hoặc ba tài liệu tương đồng. Và cũng có một số nội dung có nhiều tài liệu đề cập đến.
Tập dữ liệu được lưu trữ dưới dạng file Excel gồm 4 cột: cột thứ nhất là số thứ tự câu hỏi, cột thứ hai là cột chứa câu hỏi, cột thứ ba chứa câu trả lời dạng mã, cột thứ 4 là cột chứa câu trả lời và 500 dòng tương ứng 500 cặp câu hỏi – câu trả lời.
Đề tài trích đặc trưng văn bản bằng cách sử dụng mô hình túi từ. Quy trình trích đặc trưng văn bản bao gồm: tách từ, xây dựng từ điển và vector hóa tập dữ liệu.
Tách từ là một quá trình xử lý nhằm mục đích xác định ranh giới của các từ trong câu, cũng có thể hiểu đơn giản rằng tách từ là quá trình xác định các từ đơn, từ ghép,.. trong câu. Phương pháp tách từ được sử dụng trong đề tài là phương pháp tách từ đơn, xác định ranh giới của các từ bằng ký tự “khoảng trắng”.
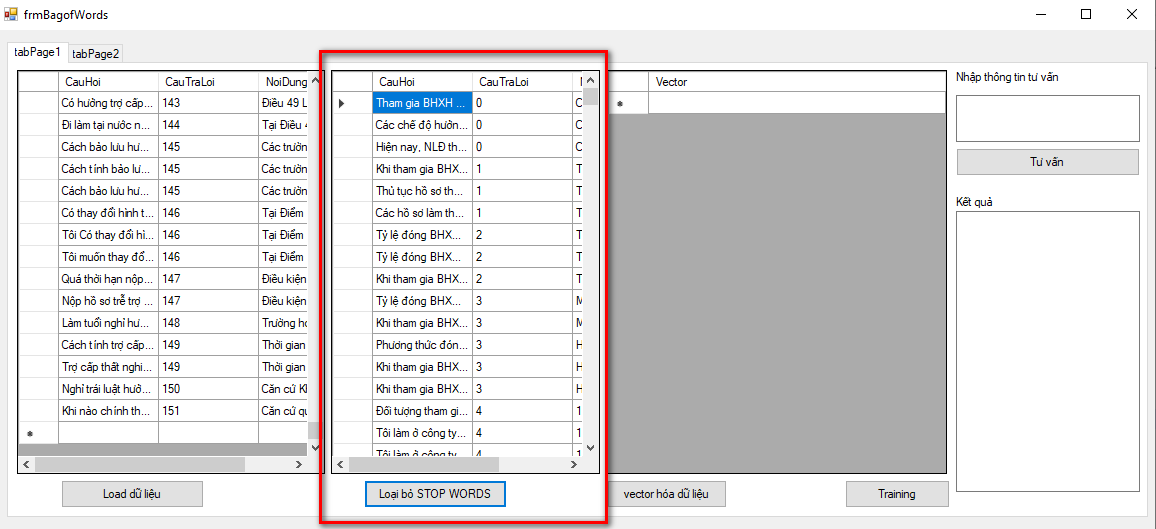
3.3.2 Xây dựng từ điển có loại stop words
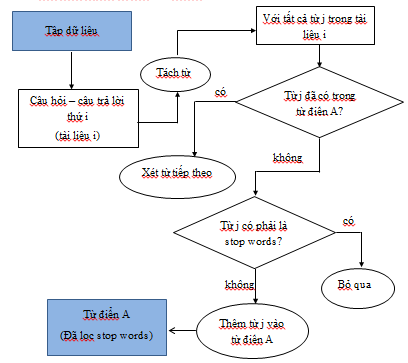
Quá trình xây dựng từ điển được mô tả như sau:
Với mỗi tài liệu (câu hỏi – câu trả lời) thực hiện:
Bước 1: Tách từ trong tài liệu thành các từ đơn
Bước 2: Với các từ đã thu được ở bước 1 nếu j không có trong từ điển A và không phải là stop words thì thêm vào từ điển A.
Từ điển sử dụng trong đề tài được xây dựng từ tập hợp tất cả các từ có trong tập dữ liệu. Do trong tập dữ liệu chứa các ký hiệu và các từ thuộc nhóm stop words đó không mang nhiều ý nghĩa nên được loại bỏ, nhằm mục đích xây dựng từ điển chỉ gồm các từ mang nhiều ý nghĩa. Cách làm này hướng tới mục tiêu giảm số chiều của các vector đặc trưng của các tài liệu trong tập dữ liệu. Từ điển được xây dựng gồm có 604 từ.
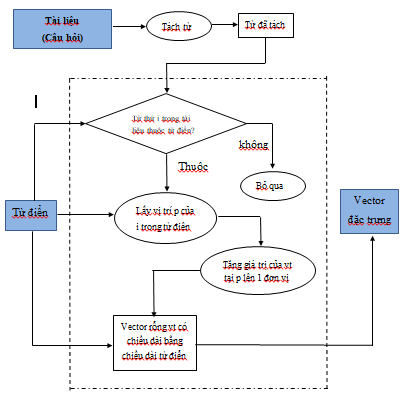
Hình 3.3: Sơ đồ quá trình tạo vector đặc trưng cho tài liệu
Quá trình tạo vector đặc trưng cho một tài liệu (câu hỏi) trong hình 3.3 được thực hiện như sau:
Bước 1: khởi tạo vector rỗng vt có chiều dài bằng chiều dài từ điển
Bước 2: tách từ của tài liệu thành các từ đơn
Bước 3: với mỗi từ tách được thực hiện:
Bước a: kiểm tra từ đã tách được có thuộc từ điển hay không, nếu thuộc thì lấy vị trí p của từ trong từ điển, nếu không thuộc thì bỏ qua.
Bước b: tăng giá trị của vector vt tại vị trí p lên 1 đơn vị
Kết thúc bước 3, thì vector vt chính là vector đặc trưng của tài liệu đầu vào
Số chiều của mỗi vector là số từ trong tập từ điển. Từ điển xây dựng được gồm có 604 từ nên mỗi vector đặc trưng có độ dài 604.
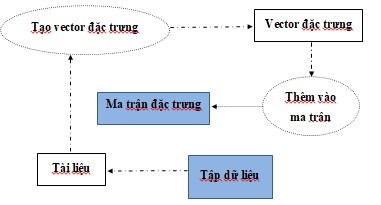
Hình 3.4: Sơ đồ quá trình tạo ma trận đặc trưng cho tập dữ liệu
Các bước thực hiện tạo ma trận đặc trưng cho tập dữ liệu:
Bước 1: Khởi tạo ma trận rổng
Bước 2: Tạo vector đặc trưng cho mỗi tài liệu trong tập dữ liệu
Bước 3: Thêm vector đặc trưng vào ma trận
Ma trận đặc trưng này (thực ra là danh sách các vector đặc trưng) có số vector đặc trưng bằng số tài liệu trong tập dữ liệu, trong đề tài là 500 tài liệu nên ma trận sẽ gồm 604 vector đặc trưng.
- col_tudien: collection từ điển, chỉ có một document duy nhất nhằm lưu trữ danh sách theo thứ tự alphabet toàn bộ các từ đơn nằm trong tập dữ liệu.
- col_danhsachvector: collection danh sách vector (chính là ma trận đặc trưng), trong đó mỗi document lưu trữ một vector tương ứng với một câu trong tập dữ liệu.
- col_cauhoi_traloi: collection câu hỏi và câu trả lời
Bộ truy vấn sử dụng trong đề tài gồm có 30 câu truy vấn, sử dụng cho việc truy vấn và đánh giá hệ thống.
Bảng 3.1: Bộ truy vấn đánh giá
|
STT
|
Câu truy vấn
|
STT
|
Câu truy vấn
|
|
1
|
ngành phục hồi chức năng
|
16
|
ưu tiên khu vực
|
|
2
|
xét tuyển đợt 2
|
17
|
thí sinh tự do
|
|
3
|
xét theo phương thức học bạ
|
18
|
chuyên ngành luật
|
|
4
|
ngành dược học
|
19
|
xét nguyện vọng 2
|
|
5
|
ngành thương mại điện tử
|
20
|
chỉ tiêu các ngành
|
|
6
|
điểm chuẩn năm 2018
|
21
|
ký túc xá
|
|
7
|
điều chỉnh nguyện vọng
|
22
|
cơ hội việc làm các ngành
|
|
8
|
tín chỉ
|
23
|
kỹ năng khi ra trường các ngành
|
|
9
|
thủ tục nhập học
|
24
|
điểm chuẩn năm 2017
|
|
10
|
hồ sơ xét học bạ
|
25
|
điểm chuẩn năm 2016
|
|
11
|
bảo lưu
|
26
|
liên thông y đa khoa
|
|
12
|
phúc khảo điểm thi
|
27
|
xét tuyển đợt 1
|
|
13
|
giấy báo trúng tuyển
|
28
|
đối tượng ưu tiên
|
|
14
|
kiểm tra năng lực tiếng Anh đầu vào
|
29
|
kỹ năng khi ra trường khối ngành y
|
|
15
|
quy định xét bổ sung
|
30
|
thi năng khiếu
|
Hệ thống gồm các chức năng:
- Chức năng truy vấn theo mô hình túi từ dùng KNN
- Chức năng truy vấn theo mô hình túi từ dùng LSI
Quy trình hoạt động của hệ thống:
- Nếu người dùng chọn phương pháp tìm kiếm theo mô hình túi từ KNN:
- Nhập câu truy vấn vào ô tư vấn.
- Hệ thống thực thi quy trình tìm theo mô hình túi từ.
- Hiển thị kết quả tư vấn nếu có kết quả phù hợp (hoặc thông báo liên hệ tư vấn viên nếu không có 1 kết quả nào là phù hợp)
2. Nếu người dùng chọn phương pháp tìm kiếm theo mô hình túi từ LSI
- Nhập câu truy vấn vào ô tư vấn.
- Hệ thống thực thi quy trình đánh chỉ mục và tính độ tương đồng của K vector.
- Hiển thị kết quả tư vấn nếu có kết quả phù hợp (với K kết quả phù hợp nhất được xếp giảm dần theo độ chính xác)
3.5.1.1 Tìm kiếm theo mô hình túi từ
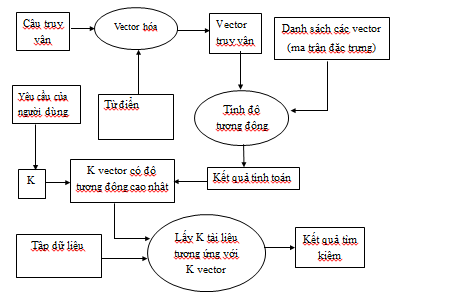
Hình 3.5: Sơ đồ tìm theo mô hình túi từ
Câu truy vấn từ phía người dùng được hệ thống xử lý theo các bước:
Bước 1: Vector hóa câu truy vấn
Bước 2: Tính độ tương đồng giữa vector truy vấn và tất cả các vector trong danh sách các vector trong cơ sở dữ liệu
Bước 3: Lấy K vector có độ tương đồng cao nhất với vector truy vấn
Bước 4: Đọc K tài liệu từ cơ sở dữ liệu tương ứng với K vector ở bước 3 để hiển thị cho người dùng.
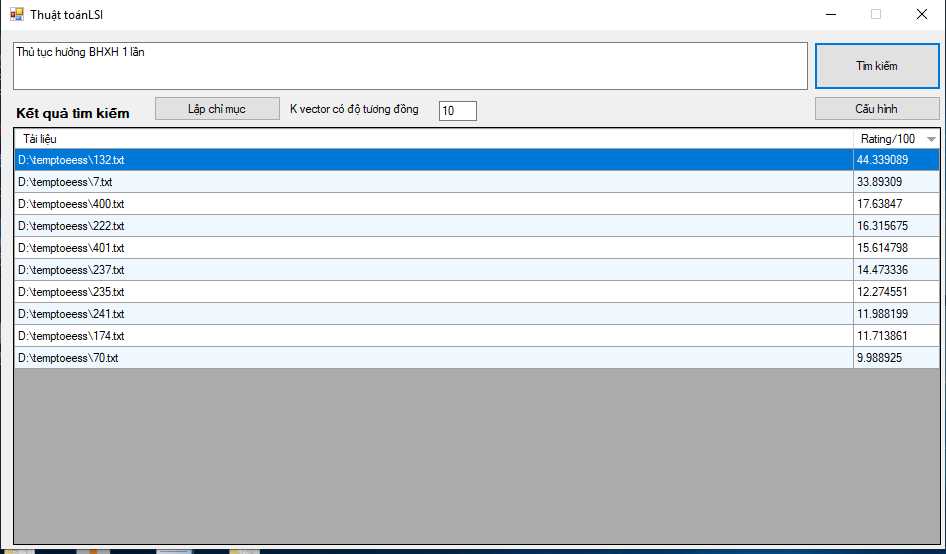
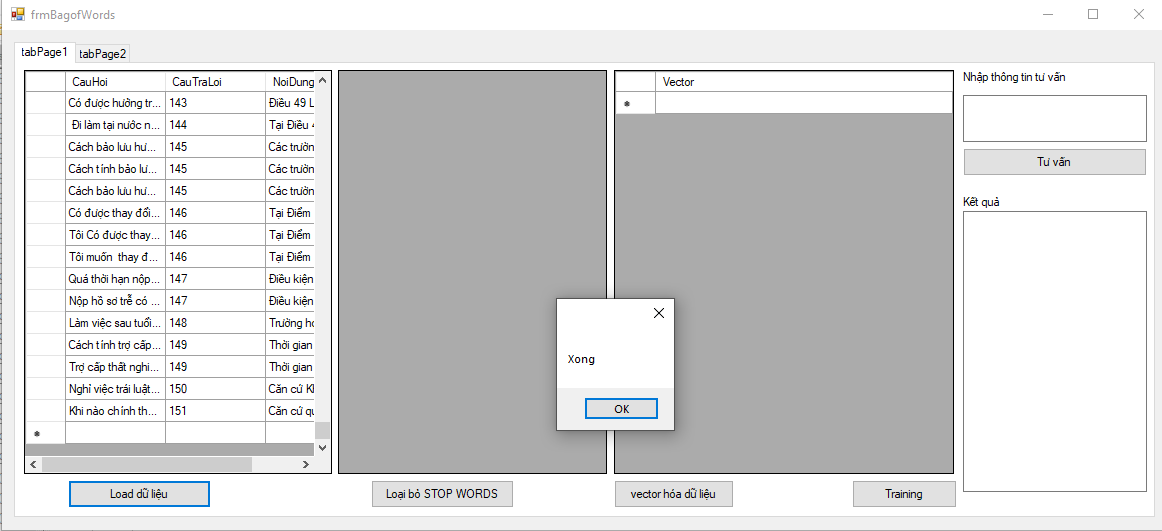
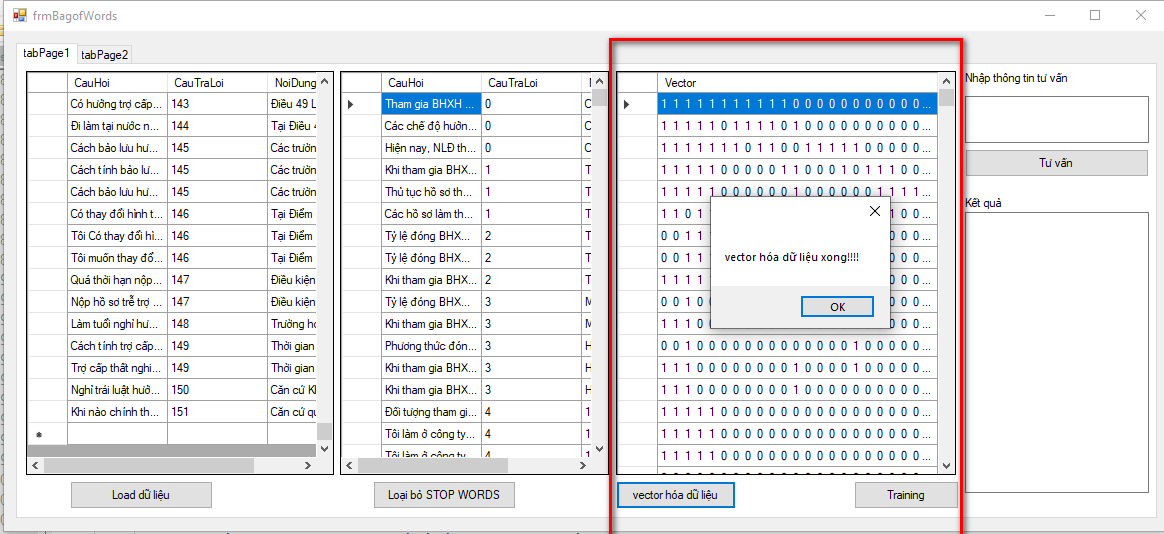
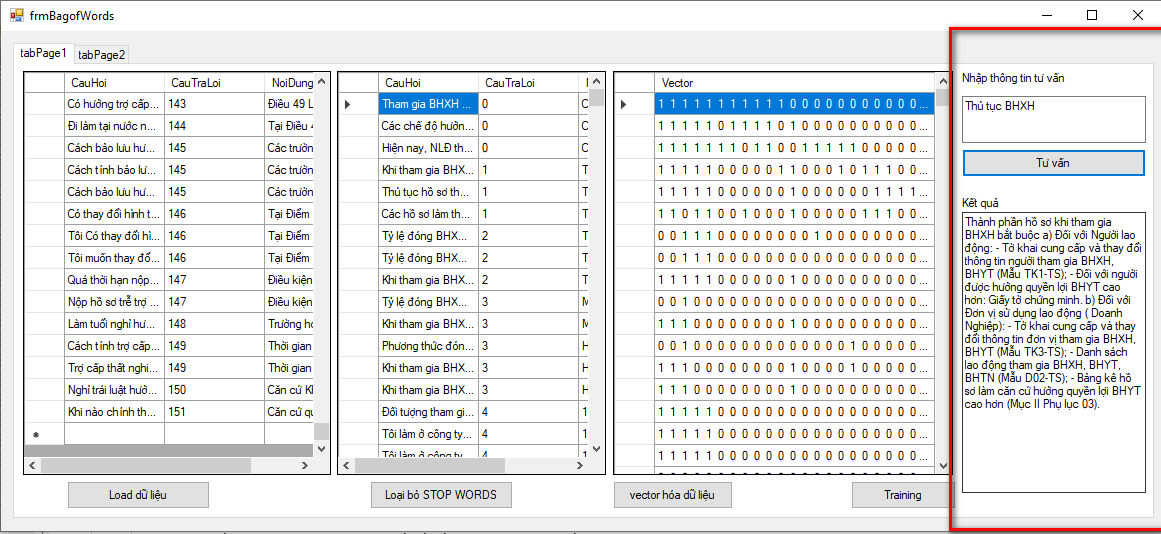
Giao diện hệ thống
- BOW - KNN
Hình 3.7: Giao diện hệ thống
Giao diện hệ thống gồm:
- Load dữ liệu
- Loại bỏ stop words
- Vector hóa
- Train
- Tư vấn
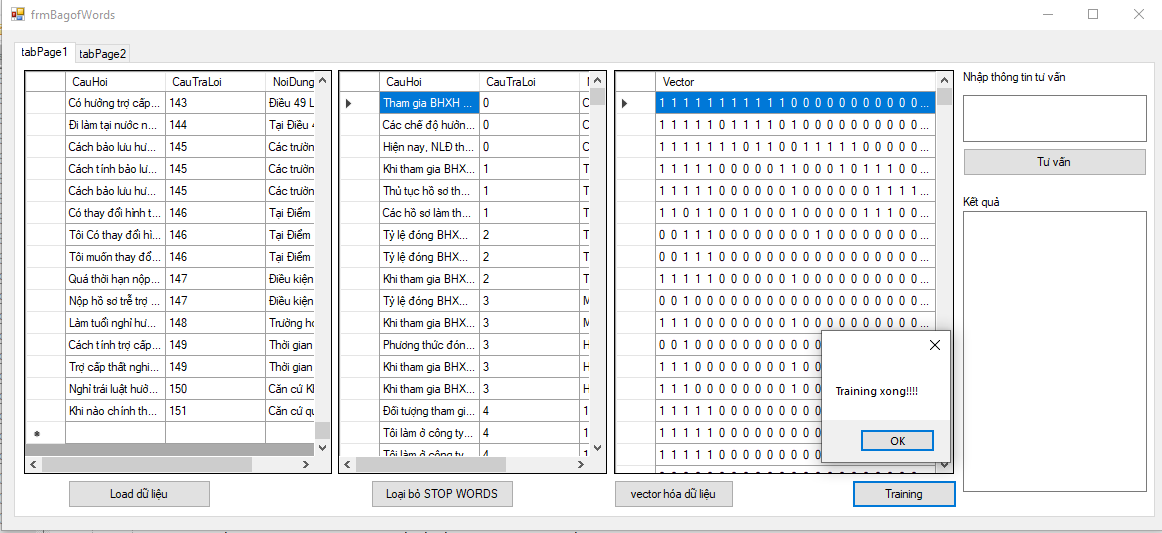
3.5.2.3 Kết quả thực hiện từng bước theo mô hình túi từ KNN
- Load dữ liệu

- Loại bỏ stop words
- Vector hóa
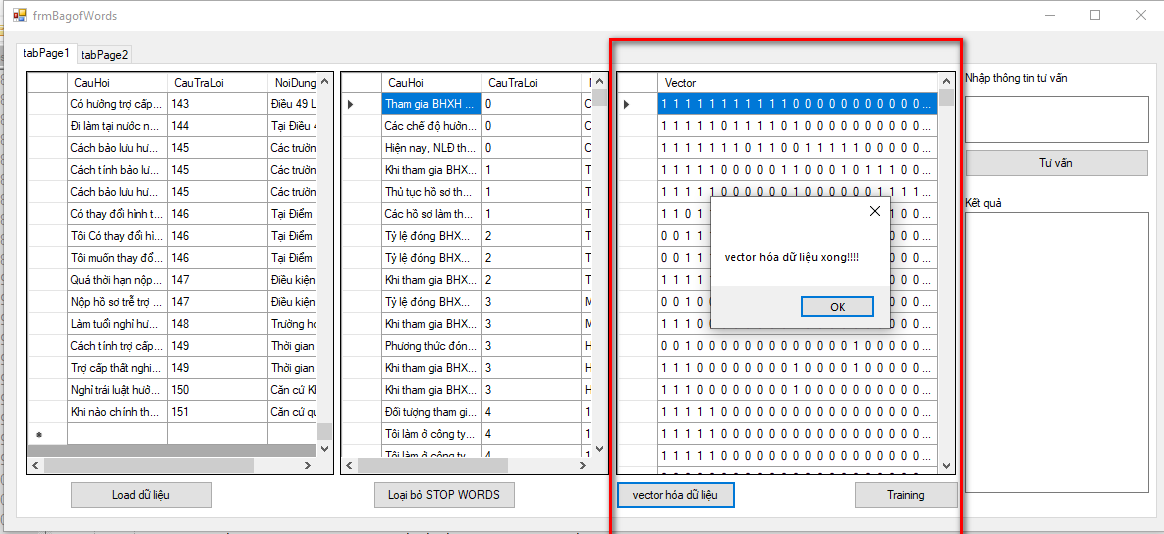
- Train
- Tư vấn
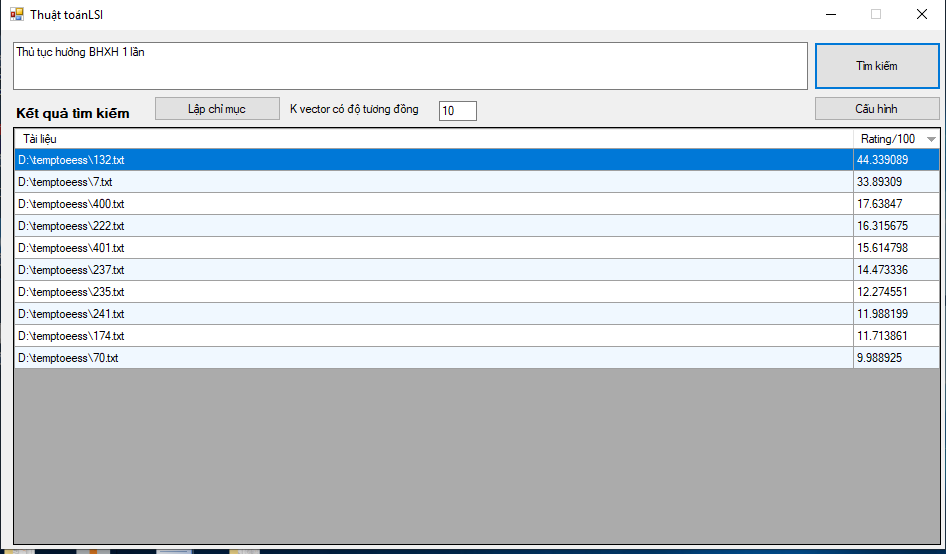
- BOW – LSI
Tạo chỉ mục
Bước 1
- Lấy nội dung các tài liệu trong thư mục chỉ định
- Tạo 1 danh sách các tài liệu hợp lệ
- Ánh xạ ID vào tên tập tin để thực hiện tính toán
- Tạo 1 danh sách words
- Duyệt từng từ trong document
- Đọc danh sách words trong document
- Lọc các stop-words từ danh sách stopword
- Duyệt từng từ:
-Lấy gốc từ sử dụng PorterStemmer algorithm
-Thêm stemmed-word (gốc từ) vào danh sách words
-Ánh xạ ID từ số sang từ - số cần thiết để tính toán
-Tạo một quan hệ Document - Word
-DocumentID and WordID (int)
Bước 2 – Tạo một Term Document Matrix (tức là tạo ma trận Word to Document như hình bên dưới)
Bước 3:
+ Lưu Ma trận Tài liệu Thuật ngữ - điều này phù hợp trong trường hợp bạn muốn sử dụng ma trận nhiều lần khi không có thay đổi đối với tài liệu.
Bước 4: Tính Term weights
+Tính trọng số local term weights
+Tính trọng số global term weights
Bước 5 - Tính toán các yếu tố Chuẩn hóa cho tài liệu (LSI dùng chuẩn hóa cosin)
Bước 6 – Tạo ma trận trọng số (Weighted term document matrix )
Bước 7 - Tính toán SVD (phân tách giá trị số ít). Trong project này DotNetMatrix sẽ tính toán cái này
Bước 8 - Bây giờ chúng ta có ma trận U, S và V từ trên xuống. Tính U (k) và S (k). K là thứ . Sau khi áp dụng xấp xỉ thứ hạng.
Bước 9 - tính S(k)- và tính nghịch đảo U(k)
Bước 10 - Lưu các tính toán này vào một tệp Index index.bin để sử dụng trong khi tìm kiếm.
Tìm kiếm (Searching)
Bước 1 - Lấy dữ liệu từ Chỉ mục index.bin đã lưu trữ. Trong trường hợp này, đó là danh sách Tài liệu, danh sách Word, S (k) -inverse, U (k), WTDM (weighted-term-document-matrix)
Bước 2 - Lấy văn bản truy vấn và lọc các stop-words và áp dụng xuất phát trên vectơ này.
Bước 3 - Tạo một vectơ bằng cách sử dụng danh sách từ - được gọi là [q (hoán vị) - qT].
Bước 4 - Chuẩn hóa qT (chuẩn hóa đơn giản).
Bước 5 - Tính toán vectơ truy vấn q = qT x U (k) x S (k) (nghịch đảo)
Bước 6 - Bây giờ chúng ta có vectơ truy vấn, tạo một vectơ tài liệu để so sánh với vectơ truy vấn
Bước 7 - tính toán sự tương đồng trong truy vấn và tài liệu.
Giao diện
- Cấu hình
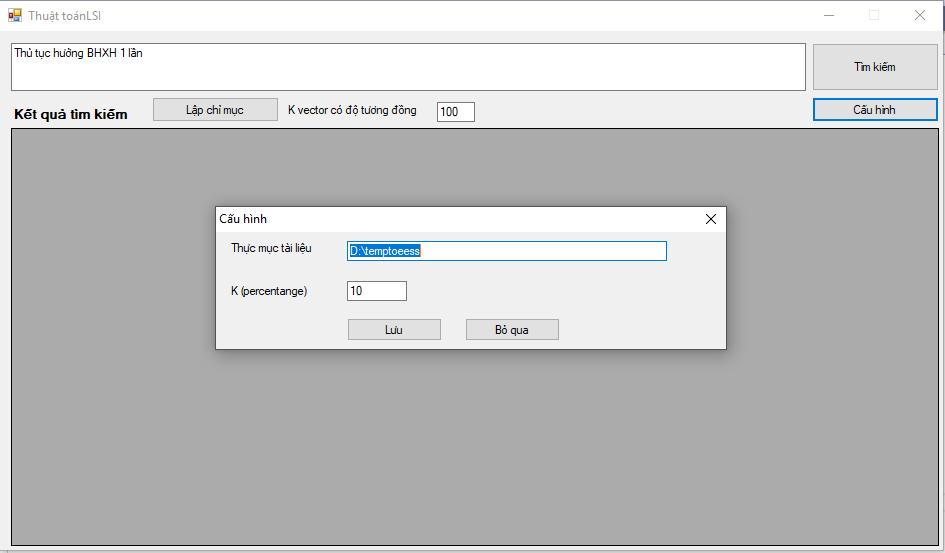
- Đánh chỉ mục
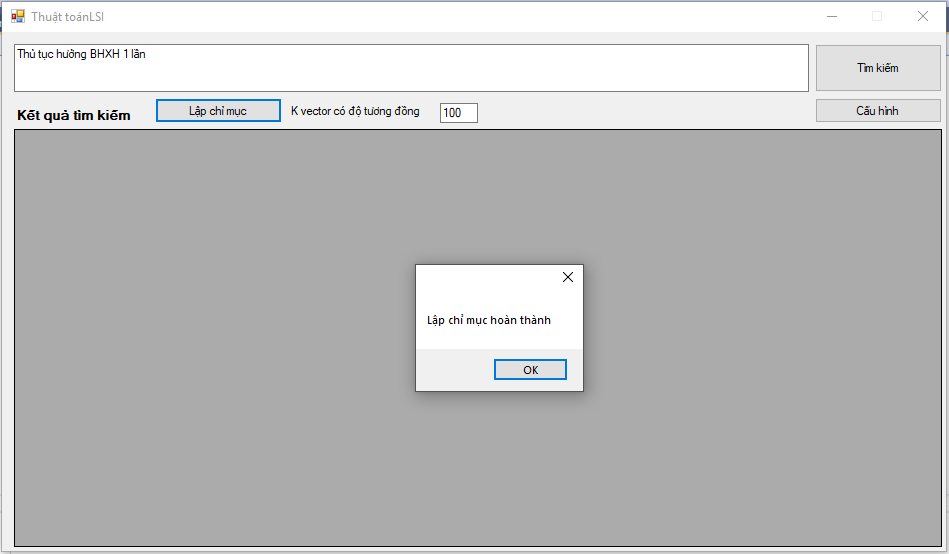
- Tìm kiếm